
In diesem Video werden wir Humata AI vorstellen, einen neuen Service, der durch Fortschritte in der künstlichen Intelligenz ermöglicht wird und von ChatGPT angetrieben wird. Gegründet im Jahr 2022 von den Unternehmern Cyrus Khajvandi und Dan Rasmuson, gewann das Projekt schnell an Fahrt und sicherte sich bedeutende Investitionen von drei großen Unternehmen, von denen eines Verbindungen zum Google-Venture-Fonds hat.

Humata AI ist im Wesentlichen ein cloudbasiertes Tool, das sein eigenes KI-Modell verwendet, um Dokumente zu analysieren und zusammenzufassen. Es ist wie Ihr persönlicher ChatGPT für Dokumente. Sie können Humata bitten, verschiedene Aufgaben zu erledigen, wie das Auffinden bestimmter Informationen, die Analyse von Text, die Extraktion bestimmter Abschnitte, und es bietet sogar Links zu den Seiten an, auf die es im Dokument Bezug nimmt. Wenn es nicht finden kann, wonach Sie suchen, schlägt es vor, im Internet zu suchen.
Klingt gut, oder? Wir bevorzugen Fakten, daher begannen wir mit dem Testen von Humata und gingen dann dazu über, seine Preise und technischen Details zu erkunden.
Testen
- Juristische Dokumente
Es ist kein Geheimnis, dass Anwälte oft mit großen Mengen an Text umgehen. Also beschlossen wir, unser Testen von Humata mit einem 15-seitigen Dokument des US-amerikanischen National Constitution Center zu beginnen. Dieses Dokument beschreibt alle 27 Änderungen an der US-Verfassung.

Wir begannen damit, das Verständnis von Humata für den Inhalt des Dokuments zu überprüfen. Wie Sie sehen können, hebt das Dokument vier Änderungsphasen hervor. Also fragten wir Humata, wie viele Änderungen während der Progressive-Ära verabschiedet wurden.
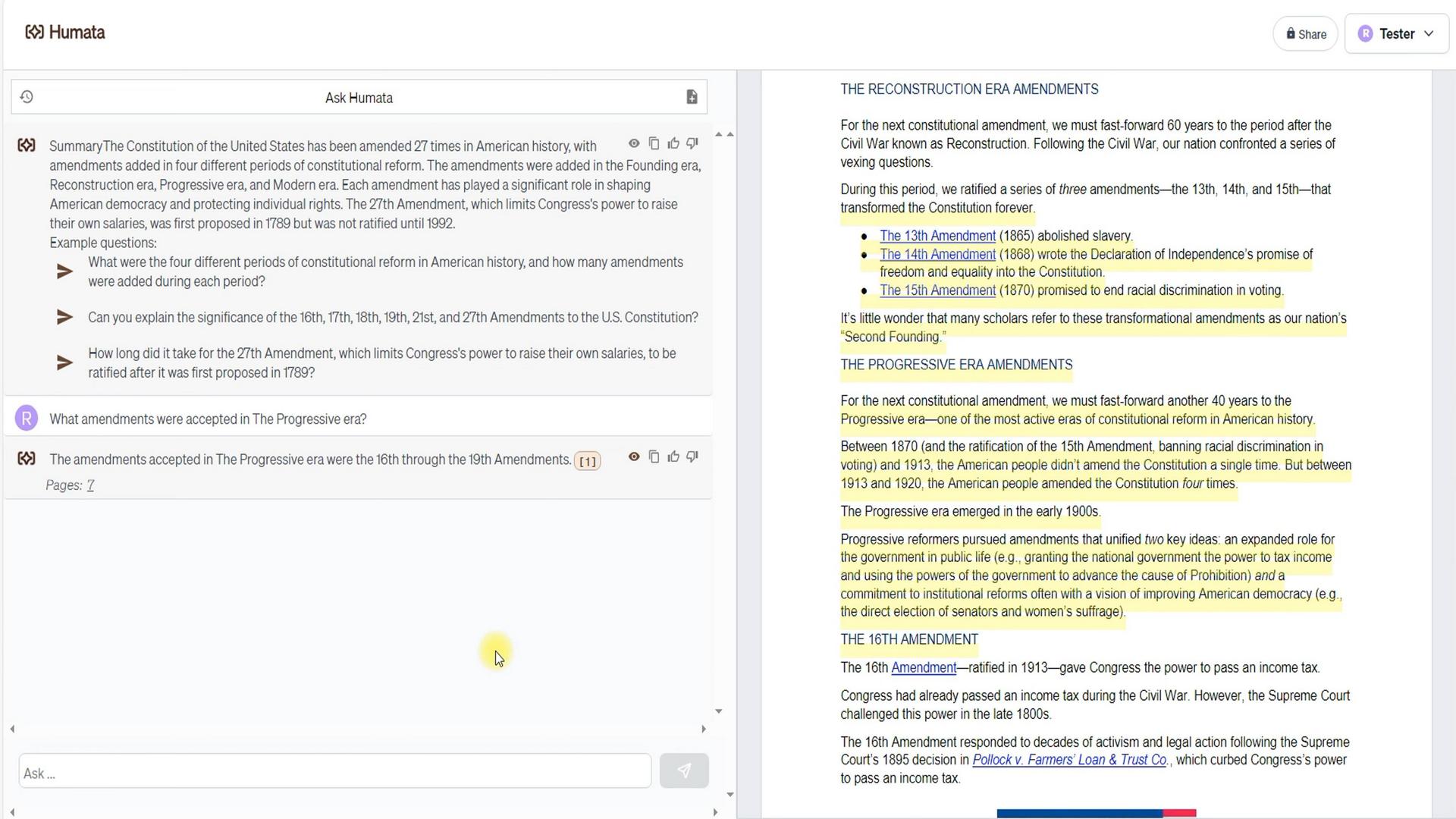
Antwort: 4. Darüber hinaus ist zu beachten, dass dies die Änderungen Nr. 16 bis Nr. 19 waren. Beachten Sie auch, dass Humata einen Link zu seiner Informationsquelle bereitgestellt hat, der uns auf Seite 7 führt. Zwischen der ersten Seite mit einer kurzen Beschreibung und der siebten mit einer ausführlichen Beschreibung entschied sich Humata also für eine detailliertere Quelle.
Dann testeten wir, wie gut Humata Texte verarbeiten kann, und baten es, kurz die Geschichte der 27. Änderung zu erzählen. Dieses Dokument widmet sich dieser Änderung viel Aufmerksamkeit.

Antwort: Im ersten Satz erhalten wir eine Beschreibung des Wesens der Änderung. Also kopiert Humata nicht einfach den passenden Text für die Antwort, sondern gibt ihn in strukturierter Form wieder. Im nächsten Satz wird die Antwort durch zusätzliche Informationen über die 200-jährige Wartezeit auf die Annahme der Änderung ergänzt.
Als nächstes testeten wir Humatas Aufmerksamkeit für Details. Wir fragten, ob James Maddson wirklich der Autor der 27. Änderung war, aber absichtlich den Namen falsch schrieben.

Antwort: Humata betrachtete dies als einfachen Tippfehler und ignorierte ihn. Es identifizierte jedoch den Namen des Gesetzgebers in der Antwort korrekt.
Also versuchten wir einen anderen Ansatz. Wir beschlossen, einen ähnlich klingenden Namen zu verwenden, zum Beispiel Jim Morrison, und fragten, ob er der Autor der 21. Änderung war.

Antwort: Humata konnte keine Antwort geben, da es keine relevanten Informationen im Dokument fand.
Um zu testen, ob Humata in seinen Antworten konsistent ist, stellten wir dieselbe Frage, führten jedoch eine Reihe von grammatikalischen Fehlern ein.

Antwort: Es ist wie zuvor. Dies ist das korrekte Verhalten für solche Sprachsysteme, da Tippfehler recht häufig sind und Systeme wie diese Anfragen auch dann verstehen sollten, wenn sie fehlerhaft sind.
Zuletzt eine knifflige Frage. “Wer war der Autor der 21. Änderung?”

Antwort: Korrekt, die Änderung hat keinen spezifischen Autor. Übrigens möchten wir darauf hinweisen, dass die Beschreibung dieser Änderung im Dokument absichtlich der 18. Änderung folgt, die sie aufgehoben hat. Humata navigiert also ausgezeichnet sowohl in der Struktur des Dokuments als auch in seinen Inhaltskomponenten.
Danach führten wir auch zahlreiche ähnliche Tests mit anderen Arten von Textdokumenten durch. Es ist nicht erforderlich, sie erneut durchzugehen, da die Ergebnisse ähnlich waren wie das Verhalten von Humata bei der Bearbeitung juristischer Dokumente. Daher werden wir nur die interessantesten Aspekte dieser Tests weiterhin hervorheben.
- Medizinische Dokumente
Für diesen Test verwendeten wir eine 21-seitige medizinische Broschüre über Schlaganfälle.
Die erste Frage zeigte, dass Humata Antworten formulieren kann, auch wenn die erforderlichen Informationen im Dokument nicht direkt angegeben sind. Wie Sie sehen können, verwendete es etwa sechs Absätze und nahm den letzten Satz als Grundlage für die Antwort. Humata schaffte es auch, Informationen aus verschiedenen Teilen des Dokuments zu organisieren und zu einer Antwort zusammenzufassen.
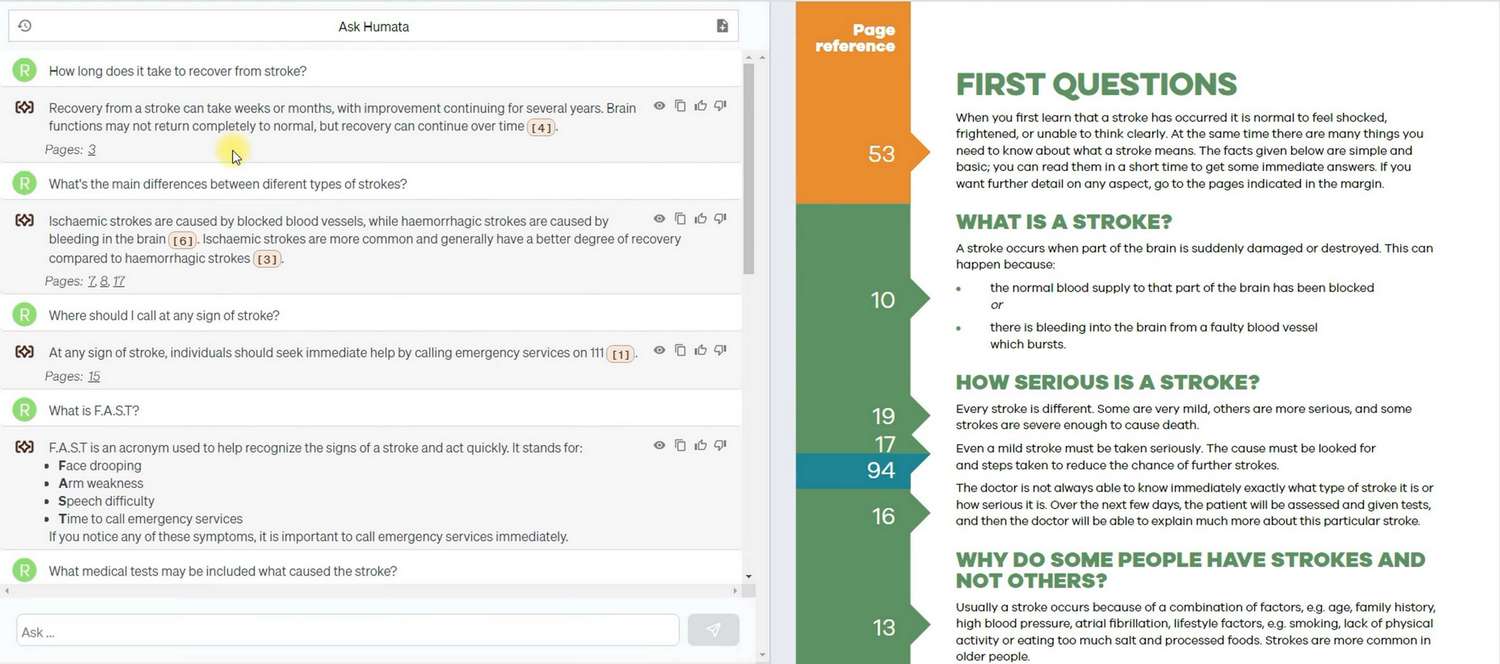
Es zeigte sich jedoch ein negativer Aspekt des Sprachmodells. Es gab eine Seite im Dokument, auf der angegeben war, welche Ärztekonsultation für einen Patienten mit einem Schlaganfall erforderlich ist. Wir formulierte eine Frage mit zwei absichtlich falschen Optionen, und Humata wählte eine davon als Antwort aus und verwendete eine externe Datenquelle als Argument. Wir überprüften diese Quelle, und die Daten waren korrekt, aber persönlich gefiel uns nicht, dass Humata sich nicht ausschließlich auf die Daten aus meiner Quelle verlassen hatte. Außerdem mussten wir Zeit damit verbringen, nach der externen Datenquelle zu suchen, die von Humata verwendet wurde, da der bereitgestellte Link bereits nicht mehr zugänglich war.
- Kulinarische Rezepte
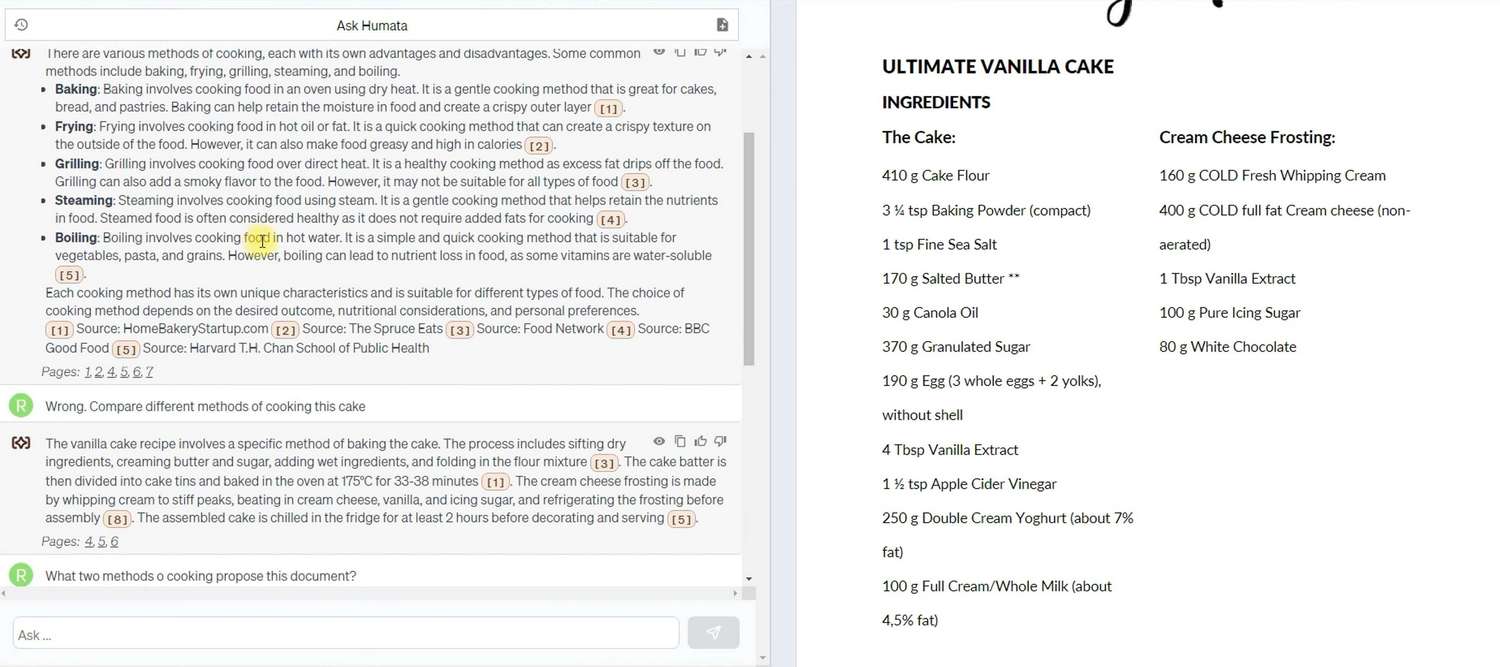
In diesem Fall war Humata noch proaktiver beim Einsatz externer Daten, aber beim Präzisieren der Fragestellung wurde es überzeugt, nur die im Dokument bereitgestellten Informationen zu verwenden. Während dieser Tests waren Humatas Fähigkeiten zum Selbstlernen und zum Verständnis des Kontexts von Benutzeranfragen offensichtlich, ähnlich wie bei den beliebten Sprachmodellen.
- Normale Texte
Dieses Dokument enthielt mehrere Bewertungen über eine einzelne Einrichtung in den USA. Es gab nur minimale Strukturierung im Dokument und informelle Sprache. Wie Sie sehen können, beschrieb Humata in der ersten Frage erschöpfend das Dokument und seine Struktur, indem es das Wesentliche von 20 Textzeilen auf 6 verdichtete.
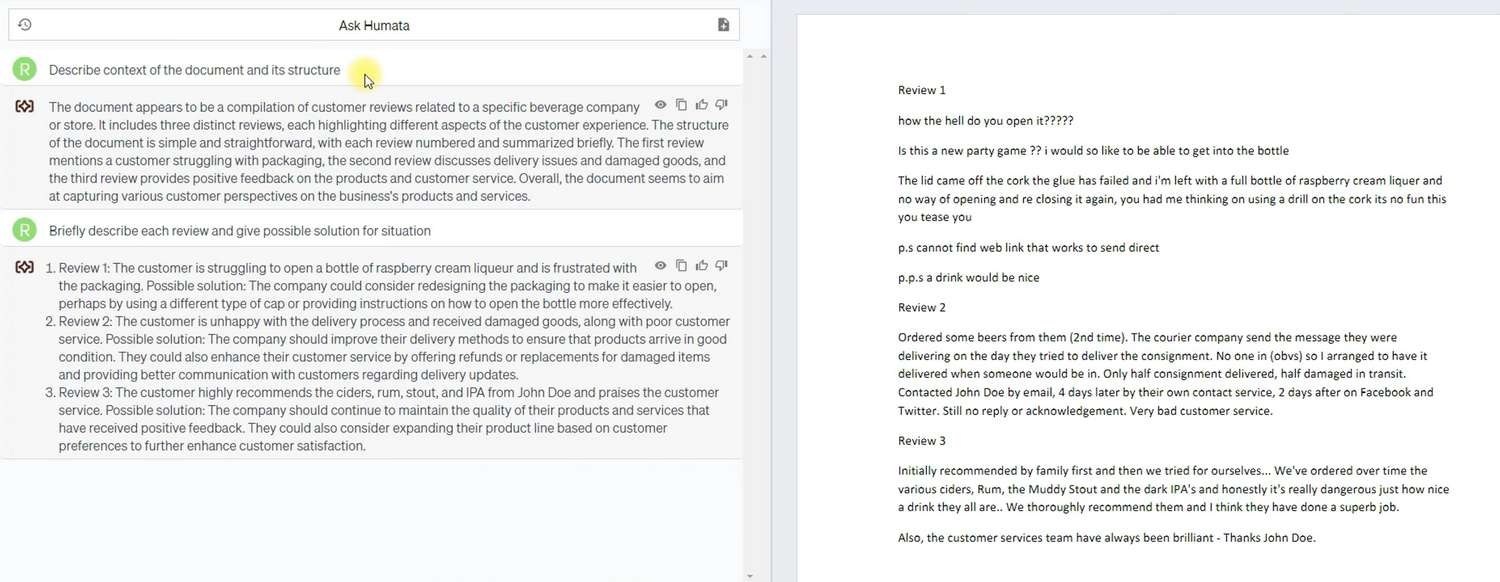
Darüber hinaus war Humata in der Lage, die Bewertungen effektiv zusammenzufassen, ohne ihren Kern zu verlieren, und gab darüber hinaus Empfehlungen entsprechend der Anfrage, wie der Eigentümer auf diese Bewertungen reagieren sollte. Wie Sie sehen können, sind die gegebenen Ratschläge ziemlich allgemein, aber dennoch bestätigen sie, dass Humata neben externen Daten und dem Dokument des Benutzers über eine umfangreiche Menge eigener Daten verfügt, die es den Benutzern zur Verfügung stellen kann.
Technische Aspekte
Da Humata ein cloudbasierter Service ist, sind seine wichtigsten technischen Merkmale Bequemlichkeit und Sicherheit. Unsere Tests haben gezeigt, dass Humata eine minimale Benutzeroberfläche hat, was die Bedienung einfach macht. Außerdem, obwohl es sich selbst als Service für PDF-Dokumente positioniert, ist es auch kompatibel mit Microsoft Word- und PowerPoint-Dateien.
Es ist auch erwähnenswert, dass unsere Tests gezeigt haben, dass es am besten mit Dokumenten funktioniert, die eine klare Textformatierung aufweisen. Wenn Ihre PDF-Datei beispielsweise ein nicht formatiertes gescanntes Dokument ist, müssen Sie die OCR-Funktion verwenden, die nur im Teamplan verfügbar ist. OCR kann auch erforderlich sein, wenn Humata eine große Anzahl von Diagrammen oder Schemata in Ihrem Dokument erkennt. Sie können jedoch immer externe OCR-Lösungen verwenden, um Ihre Dokumente mit Humata kompatibel zu machen. Fragen Sie gerne in den Kommentaren nach Hilfe, wenn Sie dabei Unterstützung benötigen.
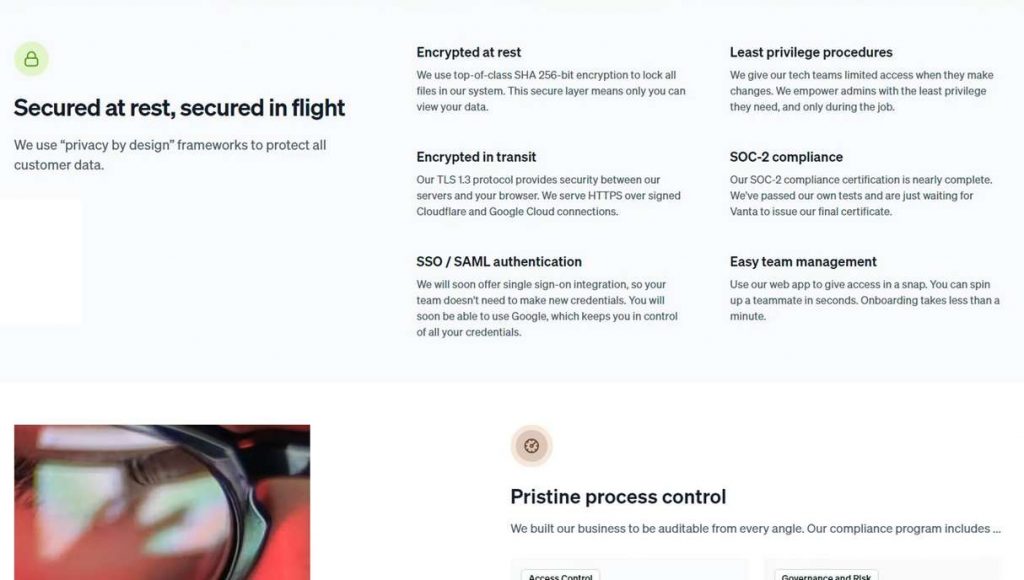
Was die Sicherheit betrifft, werden Ihre Dateien beim Senden mit dem TLS 1.3-Protokoll verschlüsselt, während gespeicherte Dateien mit dem SHA-256-Bit-Verschlüsselungsalgorithmus geschützt sind. Außerdem durchläuft der Service derzeit verschiedene Branchensicherheitszertifizierungen, einschließlich einer SOC 2-Prüfung – einem der strengsten internationalen Cybersicherheitsstandards. Kurz gesagt, diese Prüfung untersucht alle Unternehmensprozesse hinsichtlich ihrer Auswirkungen auf die Sicherheit, Verfügbarkeit, Integrität, Vertraulichkeit und Privatsphäre von Benutzerdaten.
Aber auch mit allen Zertifizierungen und Prüfungen sollten Sie sich vor dem Hochladen vertraulicher Daten in Humata mit Ihrer IT-Abteilung beraten. Wenn Sie ein Geschäftskunde sind, vermeiden Sie es, kritische Informationen wie Passwörter, Finanzdaten und Ausweise herunterzuladen, und wenn Sie ein Privatanwender sind, laden Sie keine kritischen Informationen herunter.
Preis
Die Grundlage der Preisgestaltung von Humata ist das Kontingent für die Anzahl der Seiten, die Sie scannen können. In unseren Tests haben wir den kostenlosen Plan verwendet, der das Scannen von 60 Seiten pro Monat ermöglicht. Der günstigste kostenpflichtige Plan ist nur für Studenten verfügbar und kostet 2 USD pro Monat für ein Kontingent von 200 Seiten mit der Möglichkeit, über das Limit hinaus zu scannen zu einem Preis von 2 Cent pro Seite.
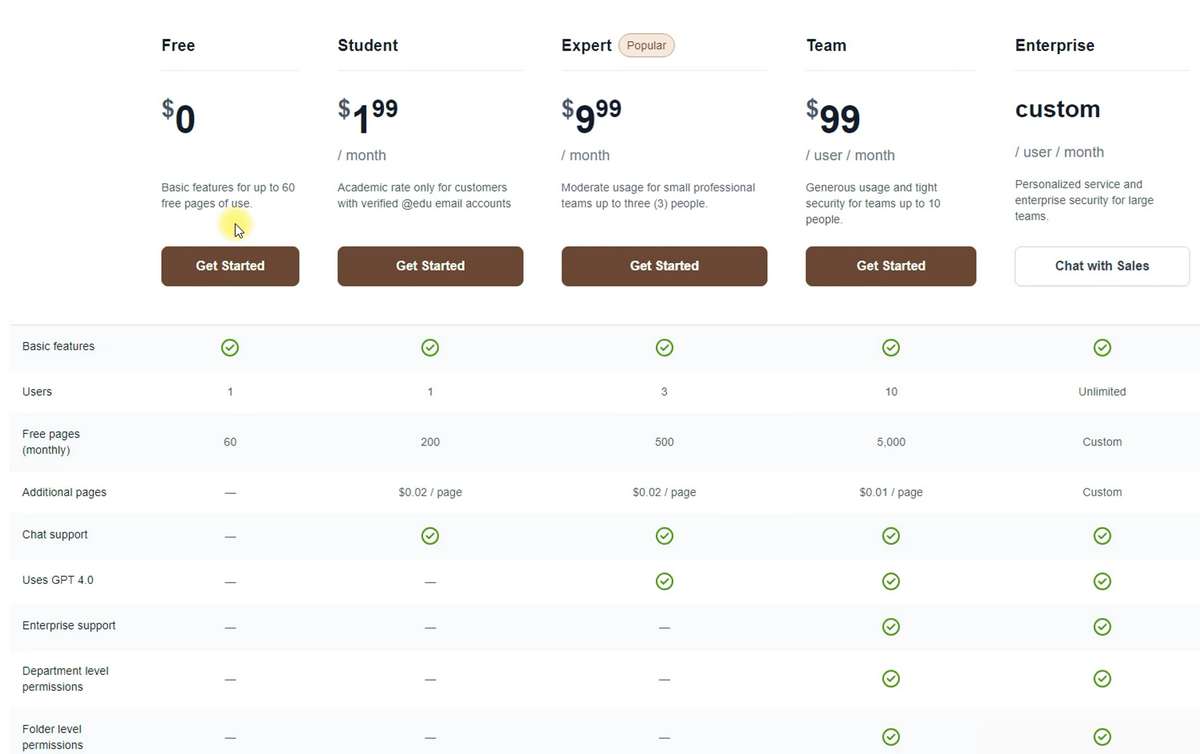
Der Basisplan kostet 10 USD für ein Kontingent von 500 Seiten, und zusätzlich zu den Vorteilen der vorherigen Pläne können Sie drei Personen zum Konto hinzufügen und auf das GPT 4.0-Sprachmodell zugreifen. Daher wird, obwohl in den günstigeren Plänen nicht direkt angegeben, wahrscheinlich das GPT 3.5-Modell verwendet.
Schließlich kostet der Premiumplan mit einem Kontingent von 5000 Seiten, reduziert auf 1 Cent pro Scan über das Limit hinaus, und der Möglichkeit, bis zu 10 Teammitglieder mit unterschiedlichen Zugriffsebenen hinzuzufügen, 100 USD pro Monat pro Benutzer. Es mag etwas überteuert erscheinen, aber für große Unternehmen wäre dies ein akzeptabler Preis für die Möglichkeit, eine interaktive Bibliothek von Arbeitsdateien mit integrierter OCR-Funktion zu erstellen.
Fazit
Humata ist ein Produkt, das auf den ersten Blick einfach erscheint, aber intern recht komplex ist. Es ist kompatibel mit wichtigen Dokumentenformaten und kann Texte aus Bildern erkennen, wenn nötig. Die KI navigiert durch die Dokumentenstruktur, versteht den Kontext, der in einer aktuellen Situation verwendet wird, und ist in der Lage, sich anzupassen, um Antworten auf spezifische Benutzeranfragen anzupassen.
Negative Aspekte können nur durch die Veraltetheit von Links zu externen Datenquellen und die Möglichkeit, das System in einer logischen Schleife zu fangen, hervorgehoben werden, wenn eine Frage gestellt wird. In Bezug auf Humata ist dies jedoch kein Problem, da der Hauptzweck dieses Dienstes die Analyse und Verarbeitung von Dokumenten ist, in der es bei Tests herausragt.
Die Zielgruppe des Dienstes sind Personen, die mit großen Textquellen arbeiten (wie Anwälte, Ärzte oder Ingenieure), aber dank seiner flexiblen Preisgestaltung ist Humata auch perfekt für den alltäglichen oder Bildungsgebrauch geeignet.
