How to get images from websites using headless browser
- Created at:
- Updated at:

Have you ever wanted to download all the images from a web page? Without right-clicking and saving one by one, that is.
You can access any site and browse it programmatically using a headless browser. And thanks to the API they provide, inspect the requests done while browsing, images among them. Then save the ones you want in files and go to the next page. Sounds right?
What is a headless browser?
A headless browser is a browser without a graphical user interface that provides automation. We can programmatically browse the Internet, follow links, scroll, click, and check for images.
We will be using Playwright for this example. Playwright is a Python library to automate Chromium, Firefox, and WebKit browsers with a single API. It is also available in other languages with a similar syntax. Porting the code below shouldn't be difficult.
Navigate to a page with Playwright
Starting from the basics, we will visit a URL and print its title. We need to import the library and launch a browser from among the three offered, for example, Chromium. Go to a sample URL, print the page's title, and close the page and the browser. That's it!
```python
from playwright.sync_api import sync_playwright
url = "https://twitter.com/rihanna"
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)
print(page.title())
# prints "Rihanna (@rihanna) / Twitter"
page.context.close()
browser.close()
```
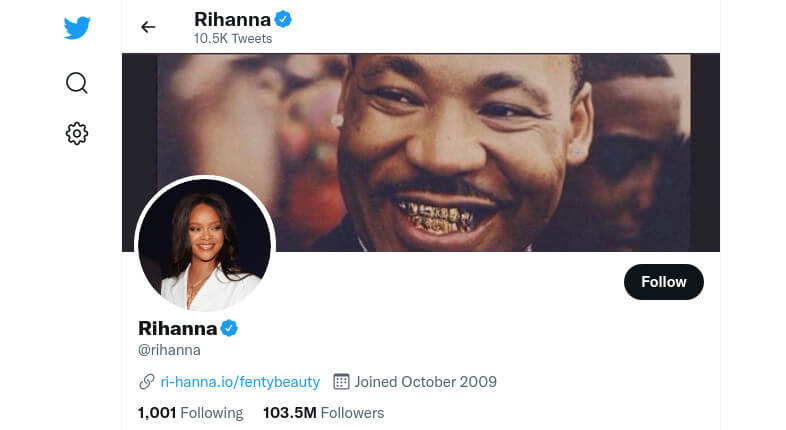
There is more work behind the scenes, automatically handled by Playwright, like waiting for the page to load and having all the content ready for us to interact with. We could tweak and configure further, but it is good enough for the moment.
Identifying images
We got the whole page loaded and printed the title, but there was no interaction with it. Anyway, the browser requested several resources behind the scenes for us: CSS files, JavaScript, images, and some more.
We can inspect that content by subscribing to a couple of events that Playwright exposes: request and response. We will look at the responses since those are the ones carrying the content we are after.
```python
page.on("response", lambda response: print("<<", response.status, response.url))
page.goto(url)
```
If we add this line before page load, we will see several URLs, 46 in our test, but it may vary. We will focus only on images. We could do that by testing the URL with string comparison or regular expressions (i.e. `
re.compile(r"\.(jpg|png|svg)$")). That would be a good option for a controlled subset of images or formats.
Filtering by resource type
But the response parameter also has a resource_type "as it was perceived by the rendering engine" that we could compare. There are several types, one of them being image. So now we can filter the images easily. We will change the code snippet to call a helper function instead of a lambda.
```python
with sync_playwright() as p:
def handle_response(response):
if (response.ok and response.request.resource_type == "image"):
print("<<", response.status, response.url)
browser = p.chromium.launch()
page = browser.new_page()
page.on("response", handle_response)
page.goto(url)
page.context.close()
browser.close()
```
It will now print only a couple of resources. We are right on track!
Downloading images
Once we identify the resources we want to store, we need to write those files to disk. We will need to open a file, write the response's body (a buffer in this case) and close the file. Luckily, handling that in Python is straightforward.
URLs can be pretty long, so we will take only the filename and truncate it to 120 characters maximum. It will prevent a "File name too long" error. For the final version, we will include error handling to avoid unexpected exceptions.
```python
import os
# ...
if (response.ok and response.request.resource_type == "image"):
# avoid "[Errno 36] File name too long"
filename = os.path.basename(response.url)[-120:]
f = open(filename, "wb")
f.write(response.body())
f.close()
```
Now we have a little problem: when visiting the page, there are a lot of images! And the script is only saving two. It looks like we need a trick.
Scroll to the end of the page
On many modern websites images are lazily loaded. That means that the browser will not download them until it needs them. And it usually translates to requesting only above a point on the page and waiting for the user to scroll to get the rest.
We can bypass that by scrolling to the bottom of the page. There are several ways to do that, but probably the easiest one (and maybe least used) is to press the "End" key. Or simulate it.
If we were to do only that, it would probably fail because the images were not ready. We need to wait for the images to load. We will instruct Playwright to wait for networkidle, which "is fired when no new network requests are made for 500 ms".
```python
page.goto(url)
page.keyboard.press("End")
page.wait_for_load_state("networkidle")
```
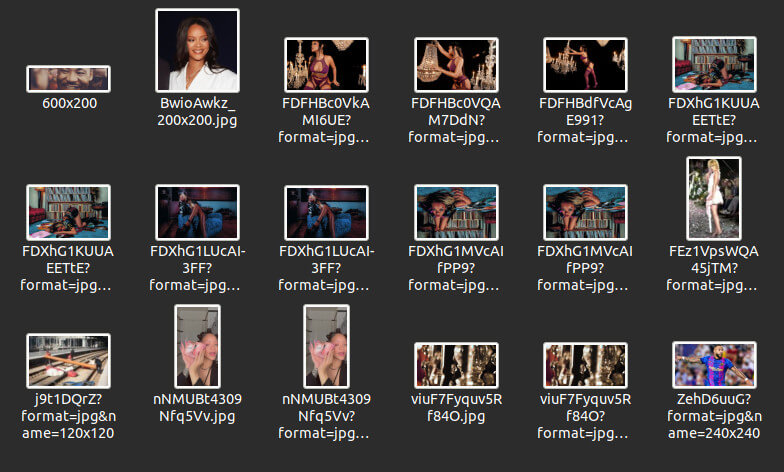
30 images! Much better now. We will add the last details.
Get only images above a specific size
To avoid downloading icons and small images such as logos, we can look at the response's content-length header. Not every request contains it, so this won't apply to every use case. Response exposes its headers in an all_headers function that returns a dictionary.
To avoid errors, we will use get to access the length. It will return a default value when it does not exist. We will use zero as default, which will discard images without the content. To save those, reverse this behavior by replacing zero with 100.
```python
int(response.all_headers().get('content-length', 0)) > 100 # arbitrary number (bytes)
```
Get images based on viewport
Sometimes websites serve different images based on the viewport, like picture tags with several sources or srcset. We can pass particular info to the browser to simulate a given resolution.
Thus we can browse on a big screen or a mobile phone, whatever suits our needs. Setting the viewport usually does the trick, but other parameters might be relevant, such as user agents or touch events.
```python
page = browser.new_page(
viewport={'width': 414, 'height': 736},
user_agent='Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'
is_mobile=True,
has_touch=True,
)
```
This set-up will simulate a mobile phone, which will show (probably) smaller or vertical images. But we can try to get the big ones by sending data from big screens or even 4k: viewport={'width': 1920, 'height': 985}.
Missing important points
Until this point, we provided the script with a fixed URL to extract images from. But that might be far from a real-world use case. A more common approach would be to provide a seed URL(s) and crawl several pages from there.
Continue crawling the website
We need to get all the links from the page, probably only the internal ones. To simplify, we will consider only the ones starting with a slash. Playwright's eval_on_selector_all function takes a selector and executes some Javascript code on them.
For our examples, we'll match a[href^='/'], which means links whose target URL starts with a slash. And then iterate over all the selected items to extract the href.
```python
links = page.eval_on_selector_all("a[href^='/']", "links => links.map(link => link.href)")
# will print: ['https://twitter.com/login', 'https://twitter.com/rihanna/following', ...]
```
Now things get complicated. We need to visit all those URLs, but avoiding duplicates, and start some queue. Or even better, parallelize the requests to go faster. As you can see, not a simple task and far from the purpose of this post. If you're interested, check out a post I wrote on web scraping and crawling in Python.
But there is even more: if we start loading several pages per second from the same domain, they will ban us.
Avoid blocks
Before explaining how to avoid blocks, please take a moment to consider the amount of traffic you are generating, mainly if you target a small website or business. They might not have the significant resources some other platforms have, like Twitter.
There are several techniques to avoid being detected and blocked by a site. The most common ones are setting custom headers and rotating proxies. Many systems block based on a combination of headers - especially user agent - and IP. With these two adequately configured, we might dodge blocks from most of the websites.
Final Code
```python
import os
from playwright.sync_api import sync_playwright
url = "https://twitter.com/rihanna"
content_length_threshold = 100
with sync_playwright() as p:
def handle_response(response):
try:
if (response.ok # successful response (status in the range 200-299)
and response.request.resource_type == "image" # it is of type image
and int(response.all_headers().get('content-length', 0)) > content_length_threshold # bigger than our threshold
):
# avoid "[Errno 36] File name too long"
filename = os.path.basename(response.url)[-120:]
f = open(filename, "wb")
f.write(response.body())
f.close()
except Exception as e:
print(e)
browser = p.chromium.launch()
page = browser.new_page()
page.on("response", handle_response)
page.goto(url)
page.keyboard.press("End") # go to the end of the page
page.wait_for_load_state("networkidle") # wait until the images are loaded
# in case we want the links to continue crawling
links = page.eval_on_selector_all("a[href^='/']", "links => links.map(link => link.href)")
page.context.close()
browser.close()
```
Conclusion
As we've seen, we can easily take advantage of Playwright responses to download images. Even filter them by name, type, or headers. There are versatile tools inside headless browsers that will help us achieve our goal.
If we were to scale it, we should put a real crawler and control logic in place. At least to do it automatically. But - as a less complex solution - adding a list of URLs and looping over them should not be complicated.
Software Developer. Building zenrows.com