
En este video, vamos a revisar Humata AI, un nuevo servicio posible gracias a los avances en inteligencia artificial, impulsado por ChatGPT. Fundado en 2022 por los empresarios Cyrus Khajvandi y Dan Rasmuson, el proyecto rápidamente ganó tracción, asegurando inversiones significativas de tres grandes empresas, una de las cuales tiene vínculos con el fondo de capital riesgo de Google.

Humata AI es esencialmente una herramienta basada en la nube que utiliza su propio modelo de IA para analizar y resumir documentos. Es como tener tu propio ChatGPT personal para documentos. Puedes pedirle a Humata que realice varias tareas como encontrar información específica, analizar texto, extraer ciertas secciones, e incluso proporciona enlaces a las páginas a las que hace referencia en el documento. Si no puede encontrar lo que estás buscando, sugiere buscar en internet.
¿Suena bien, verdad? Preferimos los hechos, así que comenzamos probando Humata y luego procedimos a explorar su precios y detalles técnicos.
Pruebas
- Documentos Legales
No es ningún secreto que los abogados suelen lidiar con grandes cantidades de texto. Entonces, decidimos comenzar nuestra prueba de Humata con un documento de 15 páginas elaborado por el Centro Nacional de la Constitución de Estados Unidos. Este documento describe las 27 enmiendas a la Constitución de los Estados Unidos.

Comenzamos revisando la comprensión de Humata del contenido del documento. Como puedes ver, el documento resalta cuatro épocas de introducción de enmiendas. Entonces le preguntamos a Humata cuántas enmiendas fueron adoptadas durante la era progresista.
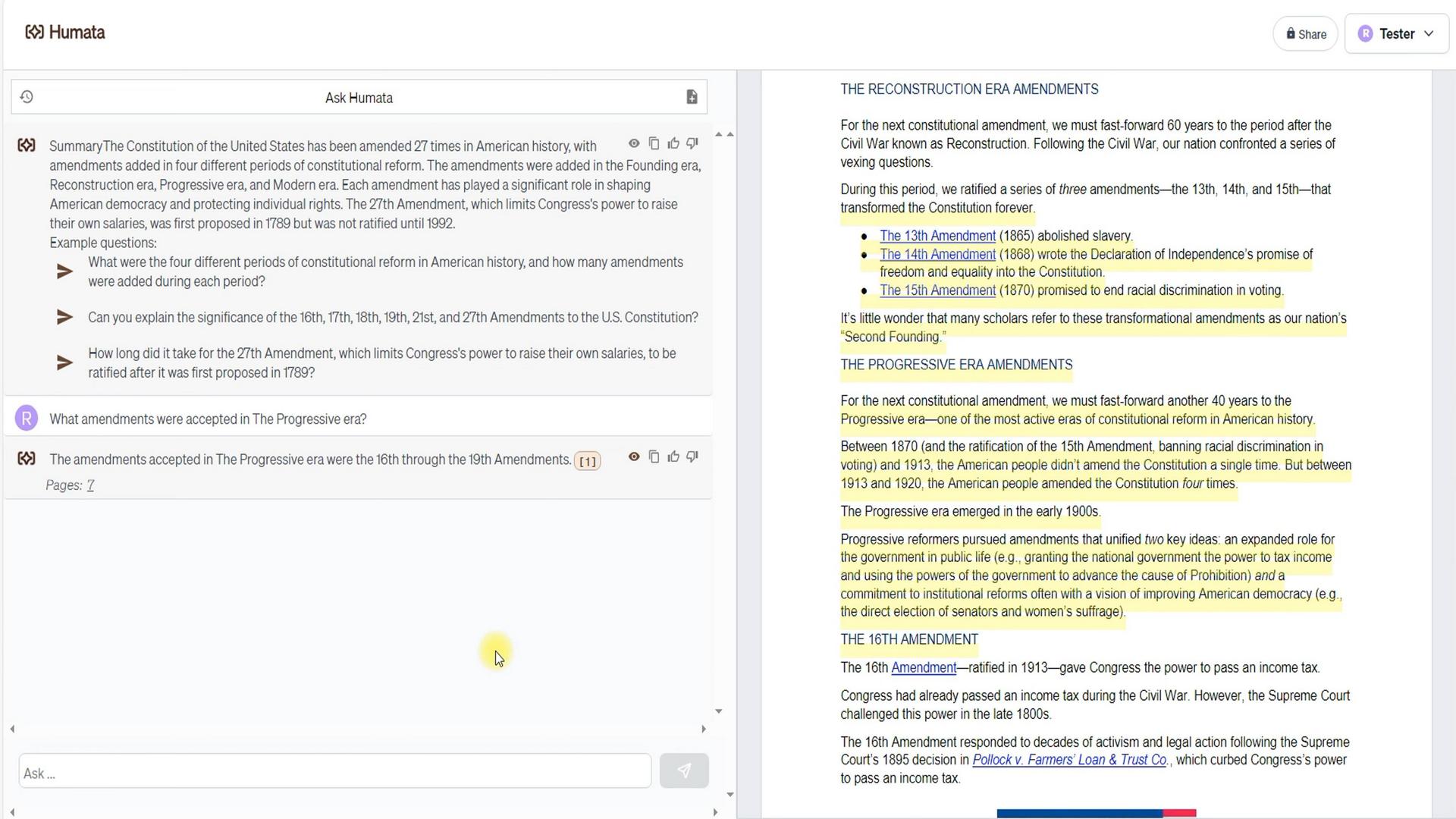
Respuesta: 4. Además, vale la pena destacar que estas fueron las enmiendas #16 a #19. Además, observa que Humata proporcionó un enlace a su fuente de información, que nos lleva a la página 7. Así que, entre la primera página con una descripción breve y la séptima con una descripción detallada, Humata optó por una fuente más detallada.
Luego, probamos qué tan bien Humata puede procesar texto y le pedimos que narrara brevemente la historia de la 27ª enmienda. Este documento presta mucha atención a esto.

Respuesta: En la primera oración, obtenemos una descripción de la esencia de la enmienda. Así que, Humata no solo copia el texto apropiado para la respuesta, sino que lo presenta de forma estructurada. En la siguiente oración, la respuesta se complementa con información adicional sobre la espera de 200 años para la adopción de la enmienda.
Luego, probamos la atención al detalle de Humata. Preguntamos si James Maddson era realmente el autor de la 27ª enmienda, pero intencionalmente mal escribimos el nombre.

Respuesta: Humata consideró esto como un simple error tipográfico y lo ignoró. Sin embargo, identificó correctamente el nombre del legislador en la respuesta.
Así que intentamos otro enfoque. Decidimos tomar un nombre similar en sonido, por ejemplo, Jim Morrison, y preguntar si él fue el autor de, digamos, la 21ª enmienda.

Respuesta: Humata no pudo proporcionar una respuesta ya que no encontró información relevante en el documento.
Para probar si Humata es consistente en sus respuestas, hicimos la misma pregunta pero introdujimos una serie de errores gramaticales.

Respuesta: Es igual que antes. Este es el comportamiento correcto para este tipo de sistemas de lenguaje porque los errores tipográficos son bastante comunes, y estos sistemas deberían entender las consultas incluso si están defectuosas.
Por último, una pregunta difícil. “¿Quién fue el autor de la 21ª enmienda?”

Respuesta: Correcto, la enmienda no tiene un autor específico. Por cierto, queremos señalar que la descripción de esta enmienda en el documento sigue intencionalmente a la 18ª enmienda que derogó. Así, Humata navega excelentemente tanto en la estructura del documento como en los elementos de su contenido.
Después de esto, también realizamos numerosas pruebas similares con otros tipos de documentos textuales. No es necesario volver a pasar por ellas ya que los resultados fueron similares a cómo se comportó Humata al tratar con documentos legales. Así que solo destacaremos los aspectos más interesantes de estas pruebas en el futuro.
- Documentos Médicos
Para esta prueba, usamos un folleto médico de 21 páginas sobre accidentes cerebrovasculares.
La primera pregunta reveló que Humata puede formular respuestas incluso cuando la información necesaria no está directamente declarada en el documento. Como puedes ver, utilizó aproximadamente seis párrafos y tomó la última oración como base para la respuesta. Humata también logró organizar información de diferentes partes del documento, consolidándola en una respuesta.
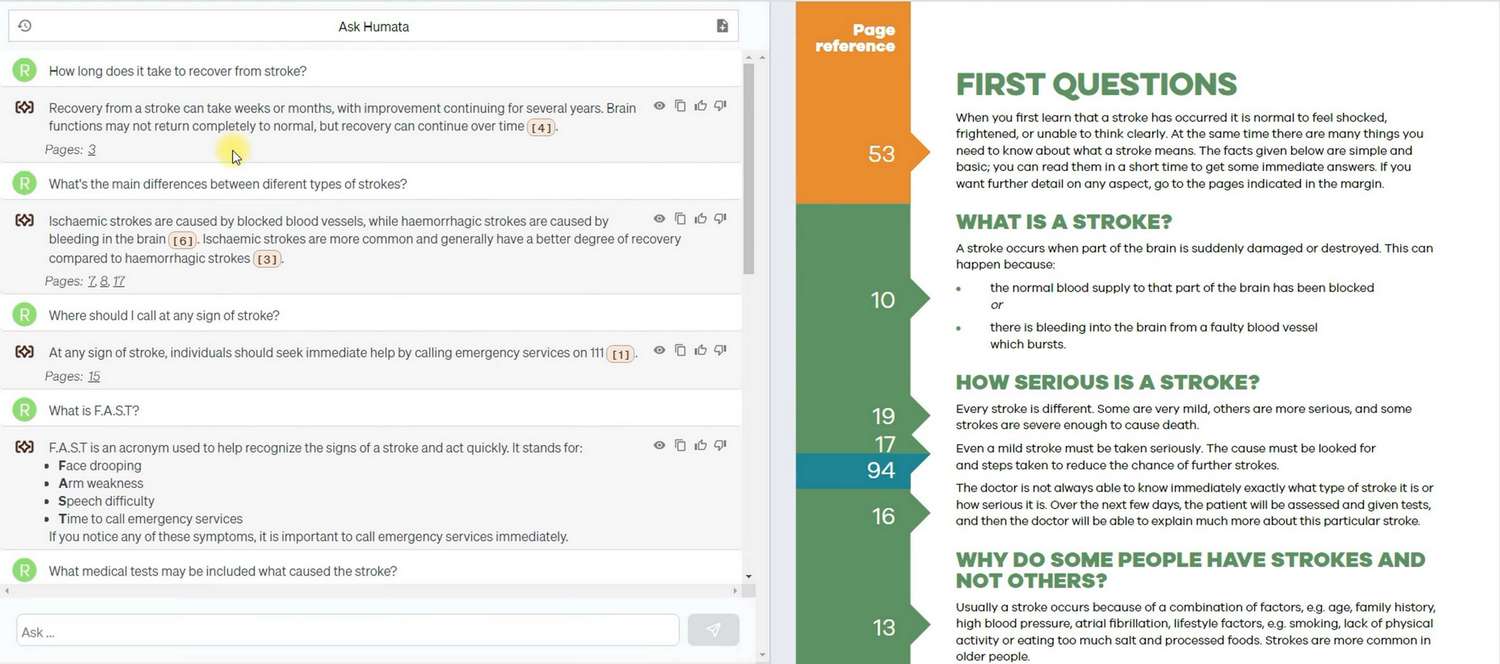
Sin embargo, aquí ha surgido un aspecto negativo del modelo de lenguaje. Hubo una página en el documento sobre qué consulta de médicos es necesaria para un paciente con un accidente cerebrovascular. Formulamos una pregunta con dos opciones falsas deliberadamente, y Humata eligió una de ellas como respuesta, utilizando una fuente de datos externa como argumento. Verificamos esta fuente, y los datos eran correctos, pero personalmente, no nos gustó que Humata no se haya basado únicamente en los datos de mi fuente. Además, tuvimos que pasar tiempo buscando la fuente de datos externa utilizada por Humata, ya que el enlace proporcionado ya no era accesible.
- Recetas Culinarias
In this case, Humata was even more proactive in utilizing external data, but upon refining the question, it was convinced to use only the information provided in the document. Throughout these tests, Humata’s abilities for self-learning and understanding the context of user queries were evident, similar to the popular language models.
- Textos Regulares
Este documento contenía varias reseñas sobre un solo establecimiento en los EE. UU. Había una mínima estructuración en el documento y un lenguaje informal. Como puedes ver, en la primera pregunta, Humata describió exhaustivamente el documento y su estructura, condensando la esencia de 20 líneas de texto en 6.
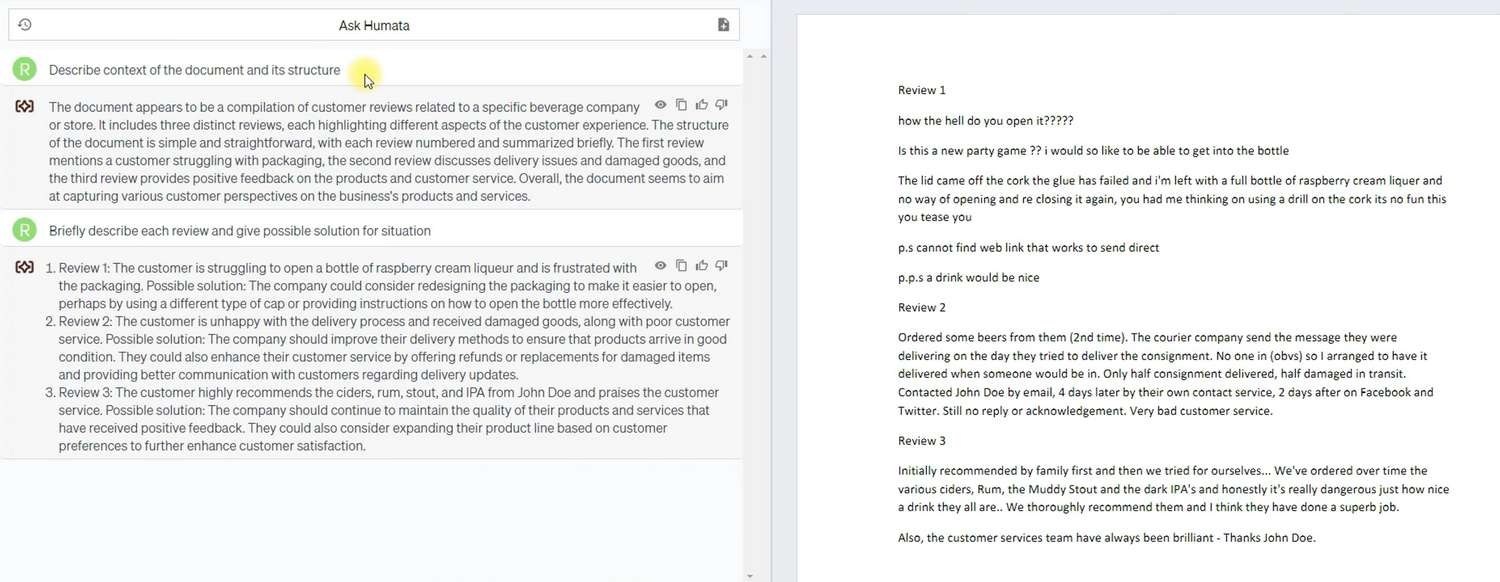
Además, Humata pudo resumir efectivamente las reseñas sin perder su esencia y, lo que es más importante, proporcionó recomendaciones según la solicitud sobre cómo debería responder el propietario a estas reseñas. Como puedes observar, el consejo dado es bastante general, pero sin embargo, confirma que además de los datos externos y el documento del usuario, Humata tiene una cantidad extensa de sus propios datos que puede proporcionar a los usuarios.
Aspectos Técnicos
Dado que Humata es un servicio basado en la nube, sus características técnicas clave son la conveniencia y la seguridad. Nuestras pruebas han demostrado que Humata tiene una interfaz mínima, lo que lo hace fácil de usar. Además, aunque se posiciona como un servicio para documentos PDF, también es compatible con archivos de Microsoft Word y PowerPoint.
También vale la pena mencionar que nuestras pruebas han demostrado que funciona mejor con documentos que tienen un formato de texto claro. Si tu archivo PDF, por ejemplo, es un documento escaneado sin formato, deberás utilizar la función de OCR, que solo está disponible en el plan Team. Es posible que también se requiera OCR si Humata detecta un gran número de diagramas o esquemas en tu documento. Sin embargo, siempre puedes utilizar soluciones de OCR de terceros para hacer que tus documentos sean compatibles con Humata. No dudes en pedir ayuda en los comentarios si necesitas ayuda con esto.
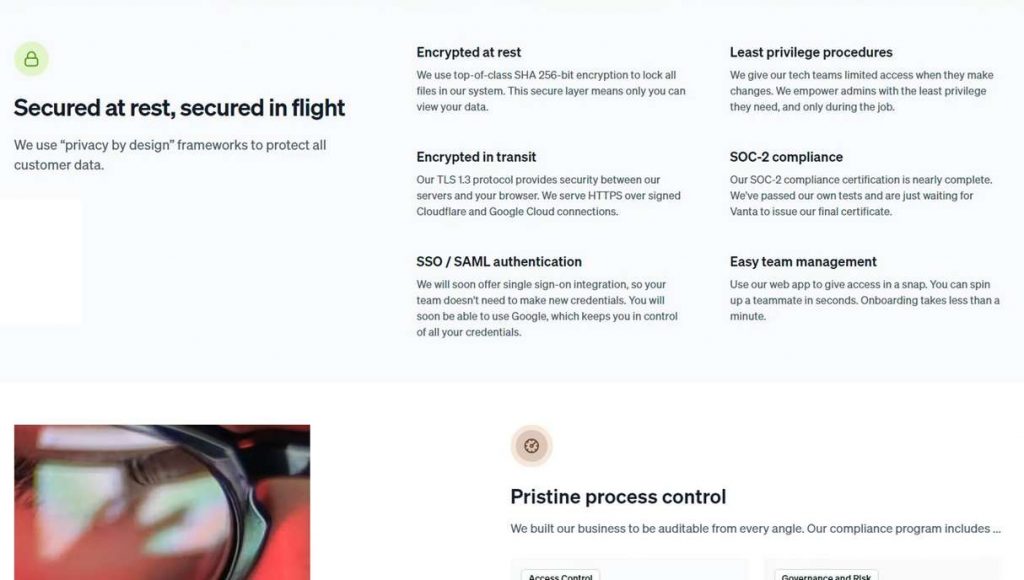
En cuanto a la seguridad, cuando envías tus archivos, se encriptan utilizando el protocolo TLS 1.3, mientras que los archivos guardados están protegidos con el algoritmo de encriptación SHA de 256 bits. Además, el servicio actualmente está pasando por diversas certificaciones de seguridad de la industria, incluida la auditoría SOC 2, uno de los estándares internacionales de ciberseguridad más rigurosos. En resumen, esta auditoría examina todos los procesos de la empresa en términos de su impacto en la seguridad, disponibilidad, integridad, confidencialidad y privacidad de los datos del usuario.
Pero incluso con todas las certificaciones y auditorías, consulta con tu departamento de TI antes de cargar datos confidenciales en Humata si eres un cliente empresarial. Si eres un usuario privado, evita descargar información crítica, como contraseñas, datos financieros e identificación.
Precio
La base de la estructura de precios de Humata es la cuota de la cantidad de páginas que puedes escanear. En nuestras pruebas, utilizamos el plan gratuito, que permite escanear 60 páginas al mes. El plan de pago más barato está disponible solo para estudiantes y cuesta $2 al mes por una cuota de 200 páginas con la capacidad de escanear por encima del límite a un precio de 2 centavos por página.
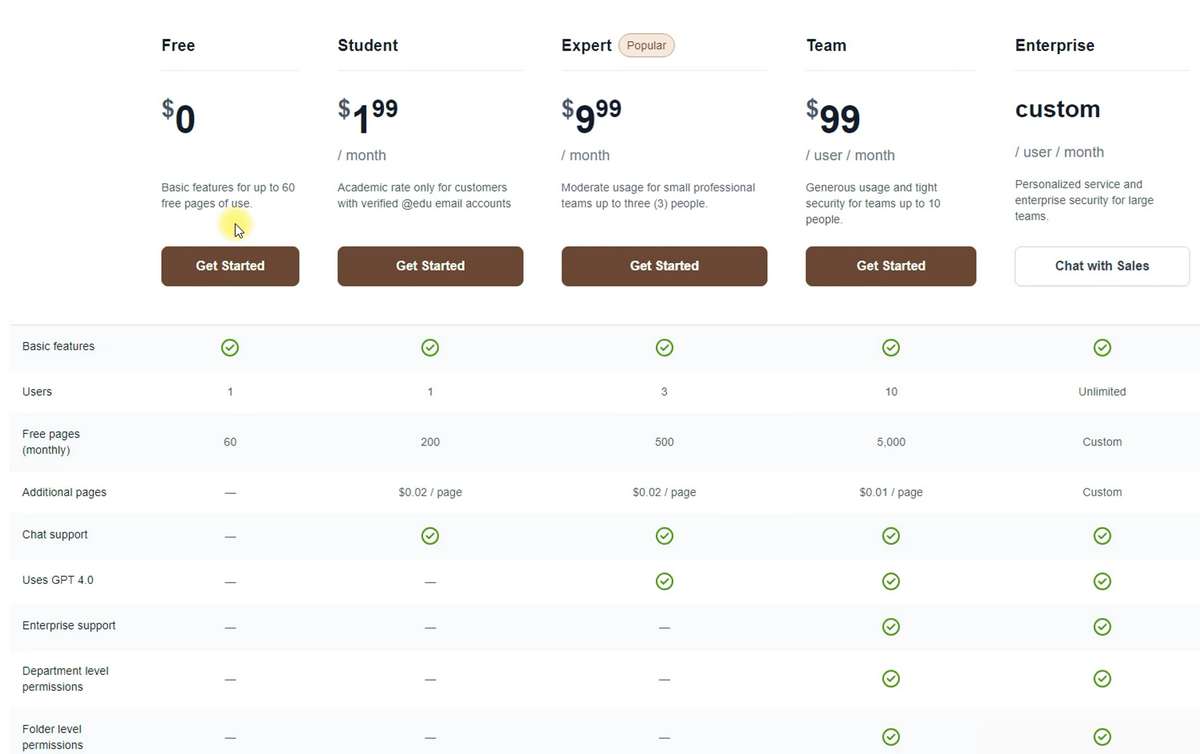
El plan básico cuesta $10 por una cuota de 500 páginas, y además de las ventajas de los planes anteriores, te permite agregar tres personas a la cuenta y acceder al modelo de lenguaje GPT 4.0. Por lo tanto, aunque no se indique directamente en los planes más económicos, es probable que se utilice el modelo GPT 3.5.
Finalmente, el plan premium con una cuota de 5000 páginas, reducida a 1 centavo por escaneo por encima del límite, y la capacidad de agregar hasta 10 miembros del equipo con diferentes niveles de acceso, costará $100 al mes por usuario. Puede parecer un poco caro, pero para empresas grandes, este sería un precio aceptable por la capacidad de crear una biblioteca interactiva de archivos de trabajo con la función de OCR incorporada.
Conclusión
Humata es un producto que parece simple en la superficie pero es bastante complejo internamente. Es compatible con los principales formatos de documentos y puede reconocer texto de imágenes si es necesario. La IA navega por la estructura del documento, entiende el contexto utilizado en una situación actual y es capaz de aprender para adaptar las respuestas a consultas específicas de usuarios.
Los momentos negativos solo pueden destacarse por la obsolescencia de los enlaces a fuentes de datos externas y la posibilidad de atrapar el sistema en un bucle lógico al hacer una pregunta. Sin embargo, en el caso de Humata, esto no es un problema, ya que el propósito principal de este servicio es el análisis y procesamiento de documentos, en lo cual sobresale en las pruebas.
La audiencia objetivo del servicio son personas que trabajan con fuentes textuales grandes (como abogados, médicos o ingenieros), pero gracias a su política de precios flexible, Humata es perfectamente adecuado para el uso diario o educativo.
