
Neste vídeo, vamos revisar o Humata AI, um novo serviço viabilizado pelos avanços em inteligência artificial, impulsionado pelo ChatGPT. Fundado em 2022 pelos empresários Cyrus Khajvandi e Dan Rasmuson, o projeto rapidamente ganhou tração, garantindo investimentos significativos de três grandes empresas, uma das quais tem laços com o fundo de investimento da Google.

O Humata AI é essencialmente uma ferramenta baseada em nuvem que utiliza seu próprio modelo de IA para analisar e resumir documentos. É como ter seu próprio ChatGPT pessoal para documentos. Você pode pedir ao Humata para realizar várias tarefas, como encontrar informações específicas, analisar texto, extrair determinadas seções e até mesmo fornecer links para as páginas referenciadas no documento. Se não conseguir encontrar o que procura, sugere pesquisar na internet.
Parece bom, não é? Preferimos fatos, então começamos testando o Humata e depois exploramos sua precificação e detalhes técnicos.
Teste
- Documentos Legais
Não é segredo que advogados frequentemente lidam com grandes quantidades de texto. Por isso, decidimos iniciar nossos testes do Humata com um documento de 15 páginas do Centro Nacional da Constituição dos EUA. Este documento descreve todas as 27 emendas à Constituição dos EUA.

Começamos verificando o entendimento do Humata sobre o conteúdo do documento. Como você pode ver, o documento destaca quatro períodos de introdução de emendas. Então, perguntamos ao Humata quantas emendas foram adotadas durante a era Progressista.
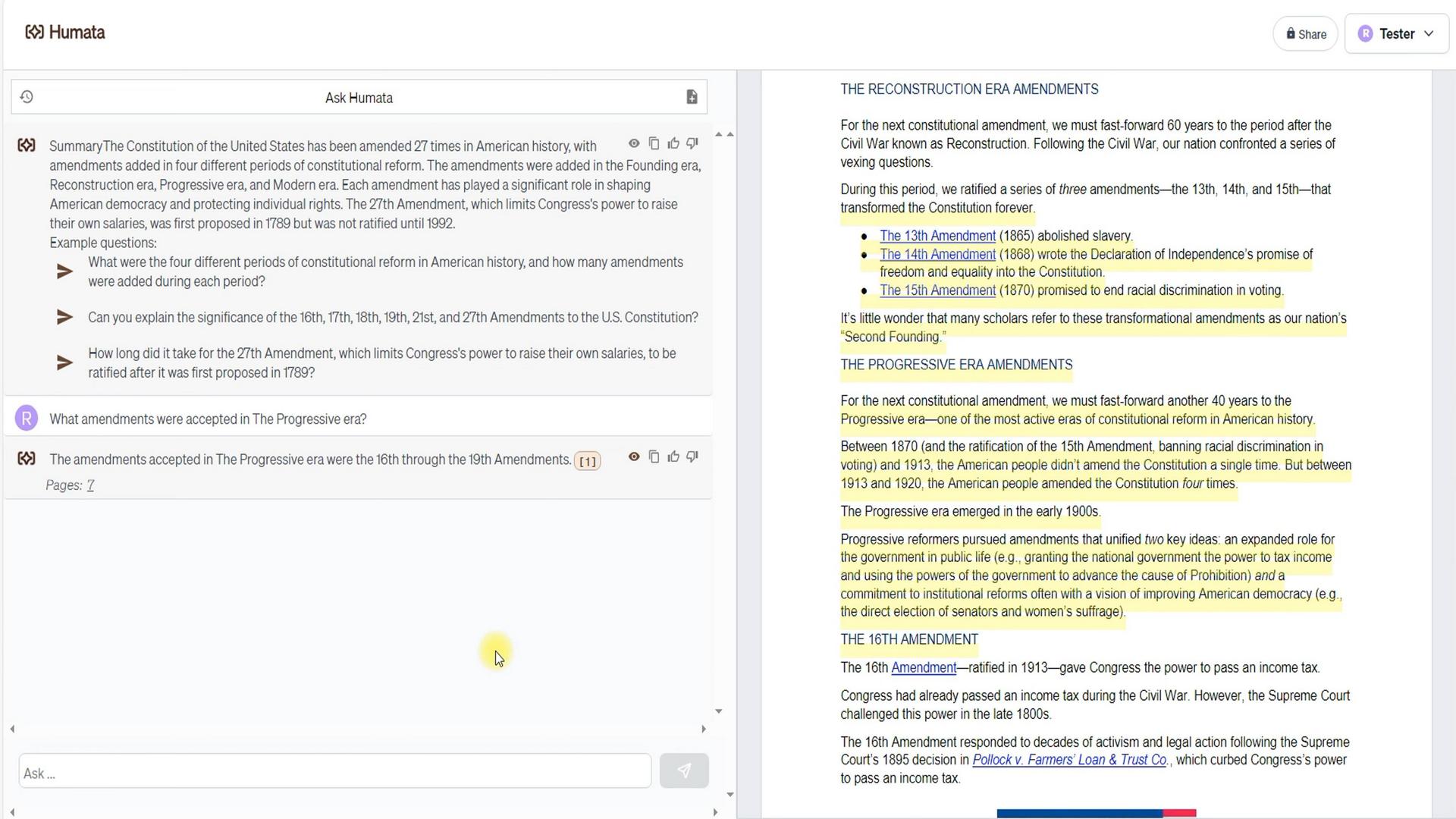
Resposta: 4. Além disso, vale ressaltar que essas foram as emendas nº 16 a nº 19. Além disso, observe que o Humata forneceu um link para sua fonte de informação, que nos leva à página 7. Assim, entre a primeira página com uma breve descrição e a sétima com uma descrição detalhada, o Humata optou por uma fonte mais detalhada.
Em seguida, testamos quão bem o Humata consegue processar texto e pedimos que narrasse brevemente a história da 27ª emenda. Este documento dá muita atenção a isso.

Resposta: Na primeira frase, obtemos uma descrição da essência da emenda. Assim, o Humata não apenas copia o texto apropriado para a resposta, mas o apresenta de forma estruturada. Na próxima frase, a resposta é complementada com informações adicionais sobre a espera de 200 anos pela adoção da emenda.
Depois, testamos a atenção aos detalhes do Humata. Perguntamos se James Maddson era realmente o autor da 27ª emenda, mas intencionalmente erramos o nome.

Resposta: O Humata considerou isso um simples erro de digitação e o ignorou. No entanto, identificou corretamente o nome do legislador na resposta.
Então tentamos outra abordagem. Decidimos usar um nome parecido, por exemplo, Jim Morrison, e perguntar se ele era o autor da, digamos, 21ª emenda.

Resposta: O Humata não conseguiu fornecer uma resposta, pois não encontrou informações relevantes no documento.
Para testar se o Humata é consistente em suas respostas, fizemos a mesma pergunta, mas introduzimos uma série de erros gramaticais.

Resposta: É o mesmo que antes. Este é o comportamento correto para tais sistemas de linguagem porque erros de digitação são bastante comuns, e sistemas como este devem entender consultas mesmo que estejam incorretas.
Por último, uma pergunta difícil. “Quem foi o autor da 21ª emenda?”

Resposta: Correto, a emenda não tem um autor específico. A propósito, queremos destacar que a descrição desta emenda no documento segue intencionalmente a 18ª emenda que ela revogou. Assim, o Humata navega excelente tanto na estrutura do documento quanto nos elementos de seu conteúdo.
Após isso, também conduzimos numerosos testes semelhantes com outros tipos de documentos textuais. Não é necessário passar por eles novamente, pois os resultados foram semelhantes ao comportamento do Humata ao lidar com documentos legais. Portanto, apenas destacaremos os aspectos mais interessantes desses testes daqui para frente.
- Documentos Médicos
Para este teste, utilizamos um folheto médico de 21 páginas sobre derrames.
A primeira pergunta revelou que o Humata pode formular respostas mesmo quando a informação necessária não é diretamente declarada no documento. Como você pode ver, ele usou aproximadamente seis parágrafos e considerou a última frase como base para a resposta. O Humata também conseguiu organizar informações de diferentes partes do documento, consolidando-as em uma resposta.
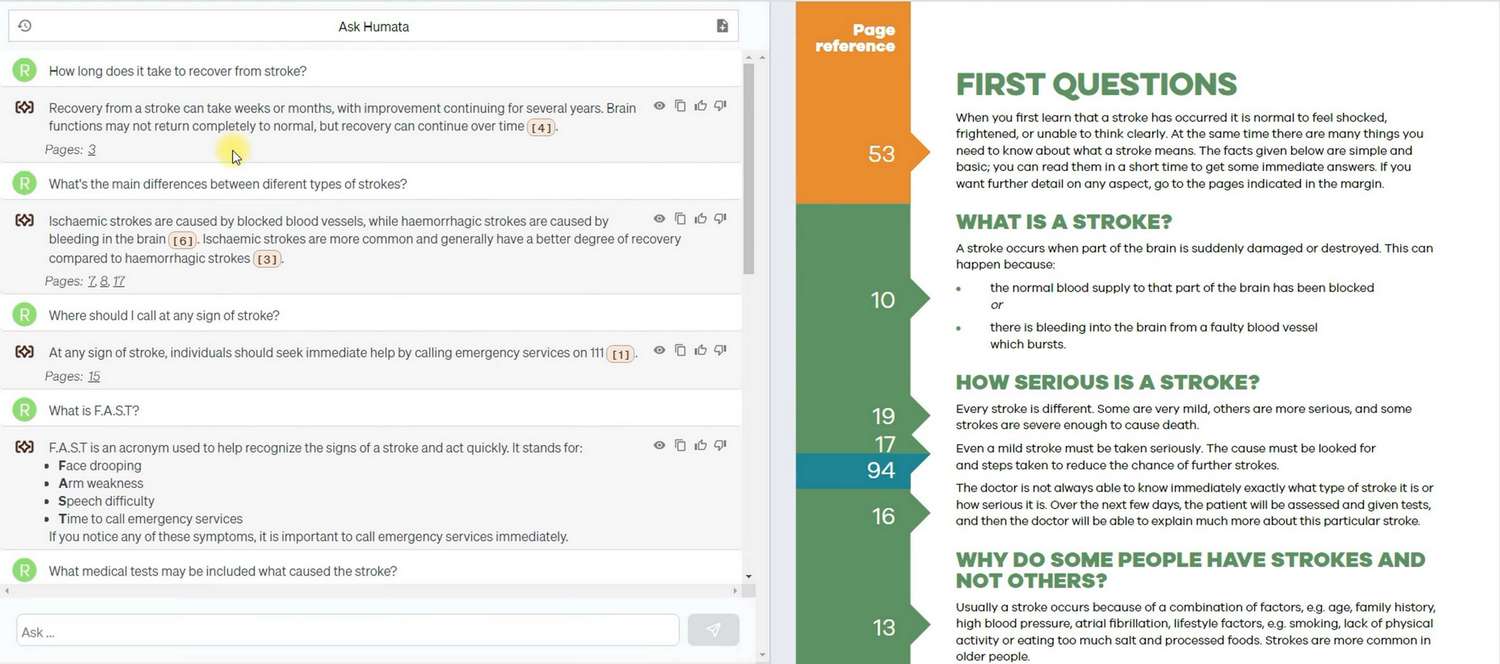
No entanto, um aspecto negativo do modelo de linguagem surgiu aqui. Havia uma página no documento sobre a qual consultas médicas são necessárias para um paciente com derrame. Formulamos uma pergunta com duas opções deliberadamente falsas, e o Humata escolheu uma delas como resposta, usando uma fonte de dados externa como argumento. Verificamos essa fonte e os dados estavam corretos, mas pessoalmente, não gostamos que o Humata não tenha confiado exclusivamente nos dados da minha fonte. Além disso, tivemos que gastar tempo procurando a fonte de dados externa usada pelo Humata, pois o link fornecido já estava inacessível.
- Receitas Culinárias
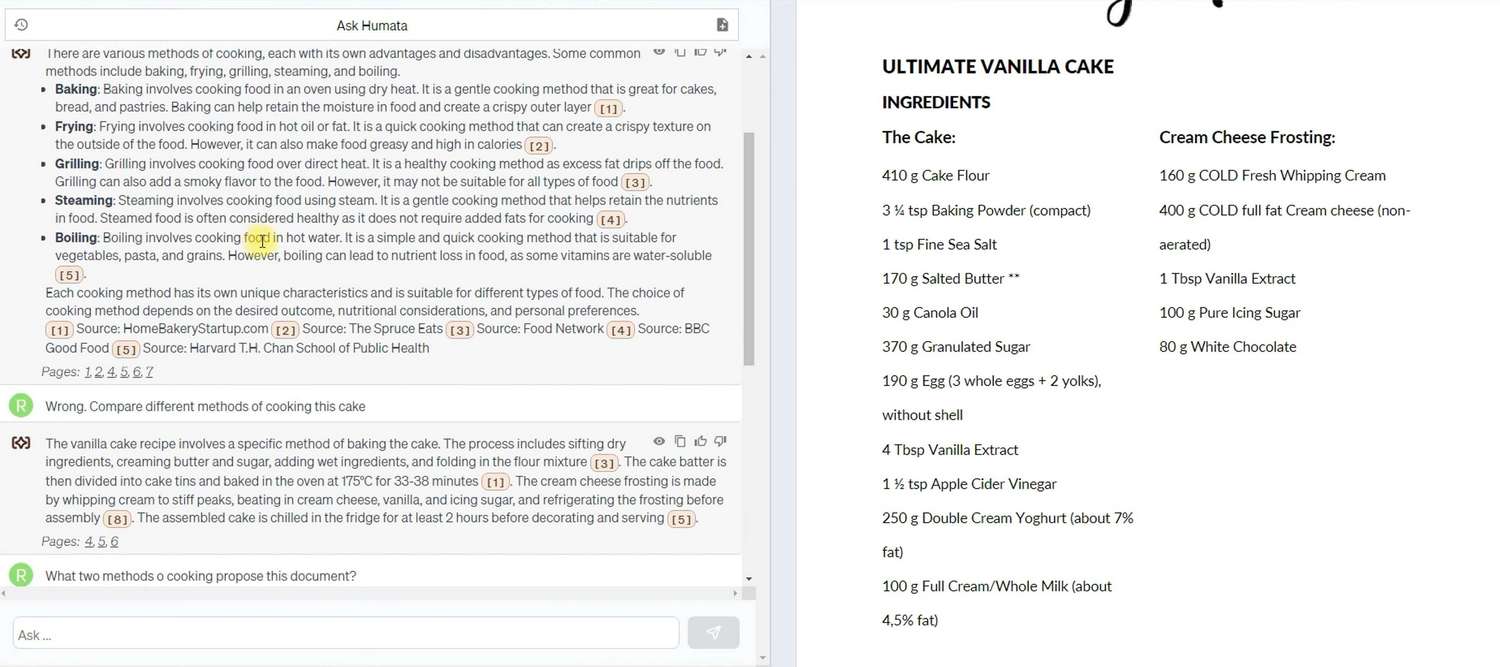
Neste caso, o Humata foi ainda mais proativo ao utilizar dados externos, mas ao refinar a pergunta, foi convencido a usar apenas as informações fornecidas no documento. Ao longo desses testes, as habilidades do Humata para autoaprendizagem e compreensão do contexto das consultas do usuário foram evidentes, semelhantes aos modelos de linguagem populares.
- Textos Regulares
Este documento continha várias avaliações sobre um único estabelecimento nos EUA. Havia pouca estrutura no documento e uma linguagem informal. Como você pode ver, na primeira pergunta, o Humata descreveu exaustivamente o documento e sua estrutura, condensando a essência de 20 linhas de texto em 6.
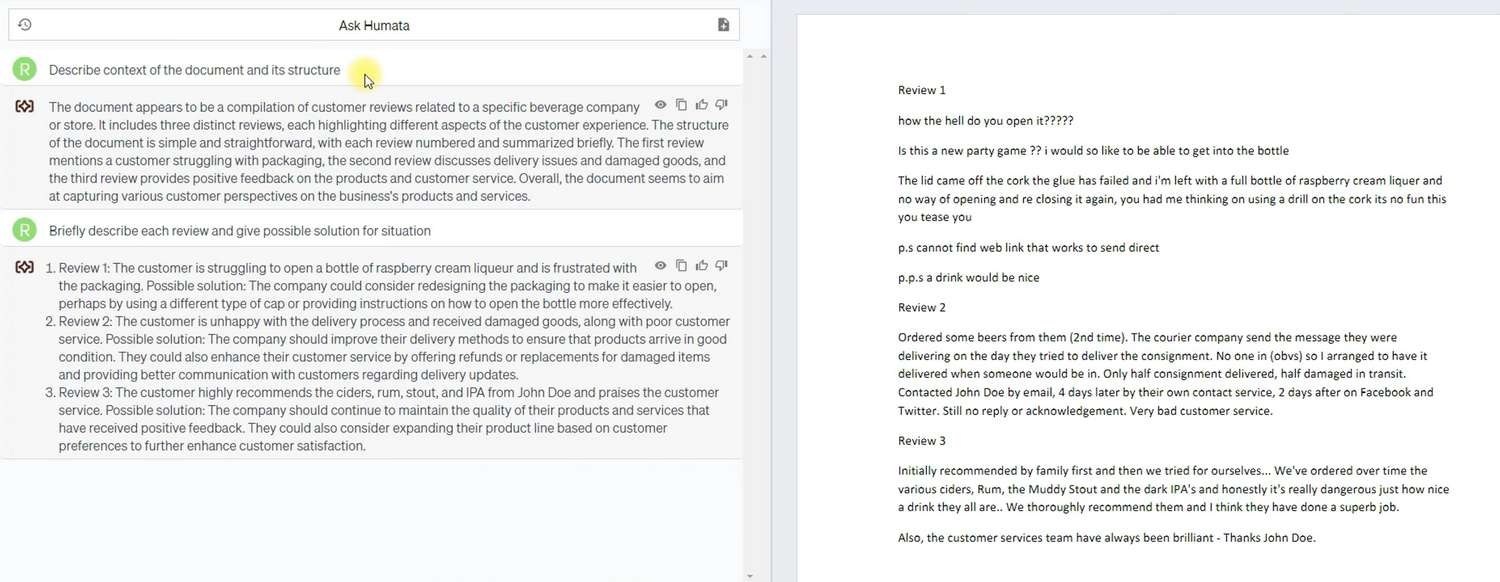
Além disso, o Humata foi capaz de resumir efetivamente as avaliações sem perder sua essência e, mais importante, forneceu recomendações de acordo com a solicitação sobre como o proprietário deveria responder a essas avaliações. Como você pode observar, o conselho dado é bastante geral, mas mesmo assim, confirma que, além de dados externos e do documento do usuário, o Humata possui uma quantidade extensa de seus próprios dados que pode fornecer aos usuários.
Aspectos Técnicos
Como o Humata é um serviço baseado em nuvem, suas principais características técnicas são conveniência e segurança. Nossos testes mostraram que o Humata possui uma interface mínima, o que facilita o uso. Além disso, embora se posicione como um serviço para documentos PDF, também é compatível com arquivos do Microsoft Word e PowerPoint.
Também vale ressaltar que nossos testes mostraram que ele funciona melhor com documentos que possuem formatação de texto clara. Se o seu arquivo PDF, por exemplo, for um documento digitalizado sem formatação, você precisará usar a função OCR, que está disponível apenas no plano Team. O OCR também pode ser necessário se o Humata detectar um grande número de diagramas ou esquemas em seu documento. No entanto, você sempre pode usar soluções de OCR de terceiros para tornar seus documentos compatíveis com o Humata. Não hesite em pedir assistência nos comentários se precisar de ajuda com isso.
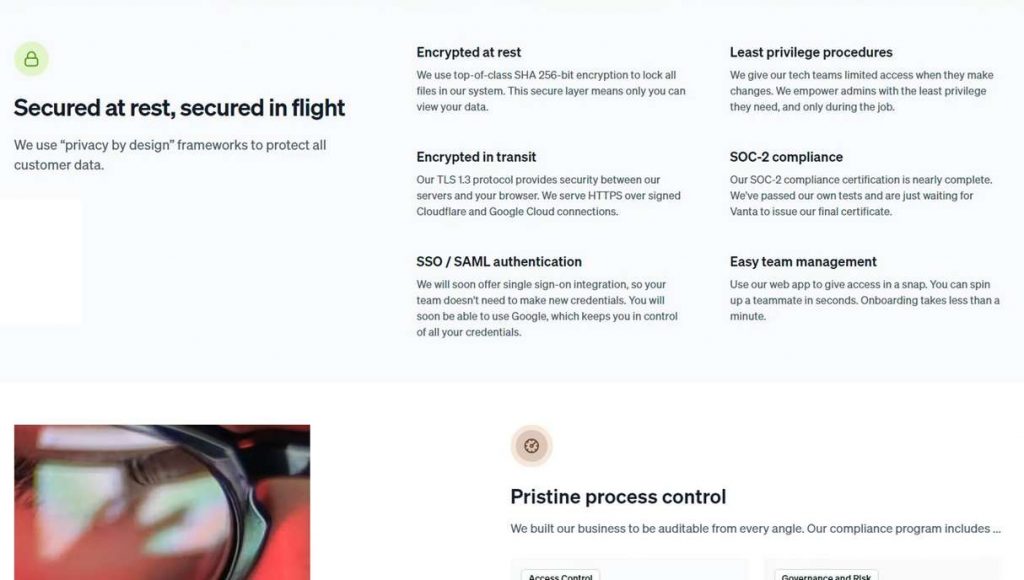
Quanto à segurança, quando você envia seus arquivos, eles são criptografados usando o protocolo TLS 1.3, enquanto os arquivos salvos são protegidos com o algoritmo de criptografia SHA de 256 bits. Além disso, o serviço está passando por várias certificações de segurança da indústria, incluindo a auditoria SOC 2 – um dos mais rigorosos padrões internacionais de cibersegurança. Em resumo, esta auditoria examina todos os processos da empresa em termos de seu impacto na segurança, disponibilidade, integridade, confidencialidade e privacidade dos dados do usuário.
Mas mesmo com todas as certificações e auditorias, consulte seu departamento de TI antes de enviar dados confidenciais para o Humata se você for um cliente empresarial. Se você é um usuário particular, evite baixar informações críticas, como senhas, dados financeiros e ID.
Preço
A base da grade de preços do Humata é a cota para o número de páginas que você pode escanear. Em nossos testes, usamos o plano gratuito, que permite escanear 60 páginas por mês. O plano pago mais barato está disponível apenas para estudantes e custa $2 por mês para uma cota de 200 páginas, com a capacidade de escanear acima do limite a um preço de 2 centavos por página.
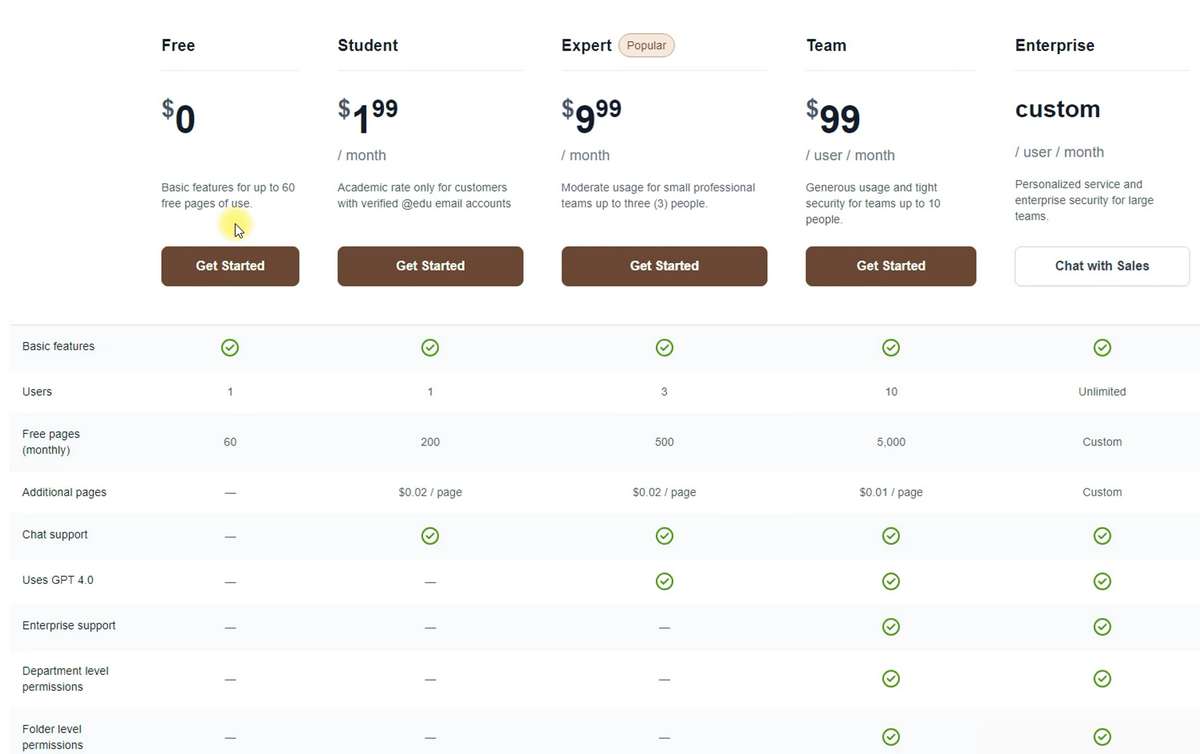
O plano básico custa $10 para uma cota de 500 páginas, e além das vantagens dos planos anteriores, permite adicionar três pessoas à conta e acessar o modelo de linguagem GPT 4.0. Portanto, embora não seja diretamente declarado nos planos mais baratos, é provável que o modelo GPT 3.5 seja utilizado.
Por fim, o plano premium com uma cota de 5000 páginas, reduzido para 1 centavo por escaneamento acima do limite, e a capacidade de adicionar até 10 membros da equipe com diferentes níveis de acesso custará $100 por mês por usuário. Pode parecer um pouco caro, mas para grandes empresas, este seria um preço aceitável pela capacidade de criar uma biblioteca interativa de arquivos de trabalho com recurso de OCR integrado.
Conclusão
O Humata é um produto que parece simples na superfície, mas é bastante complexo internamente. É compatível com os principais formatos de documentos e pode reconhecer texto de imagens, se necessário. A IA navega na estrutura do documento, entende o contexto usado em uma situação atual e é capaz de aprender para adaptar as respostas a consultas específicas do usuário.
Momentos negativos podem ser destacados apenas pela obsolescência de links para fontes de dados externas e a possibilidade de prender o sistema em um loop lógico ao fazer uma pergunta. No entanto, no caso do Humata, isso não é um problema, pois o principal objetivo deste serviço é a análise e processamento de documentos, no qual se destaca nos testes.
O público-alvo do serviço são pessoas que trabalham com grandes fontes textuais (como advogados, médicos ou engenheiros), mas graças à sua política de preços flexível, o Humata é perfeitamente adequado para uso diário ou educacional.
