
Dans cette vidéo, nous allons passer en revue Humata AI, un nouveau service rendu possible par les avancées en intelligence artificielle, piloté par ChatGPT. Fondé en 2022 par les entrepreneurs Cyrus Khajvandi et Dan Rasmuson, le projet a rapidement gagné en traction, sécurisant d’importants investissements de trois grandes entreprises, dont l’une est liée au fonds de capital-risque de Google.

Humata AI est essentiellement un outil basé sur le cloud qui utilise son propre modèle d’IA pour analyser et résumer des documents. C’est comme avoir votre propre ChatGPT personnel pour les documents. Vous pouvez demander à Humata d’effectuer diverses tâches telles que trouver des informations spécifiques, analyser du texte, extraire certaines sections, et il fournit même des liens vers les pages auxquelles il fait référence dans le document. S’il ne trouve pas ce que vous cherchez, il suggère de rechercher sur Internet.
Ça a l’air bien, n’est-ce pas? Nous préférons les faits, alors nous avons commencé par tester Humata, puis nous avons exploré sa tarification et ses détails techniques.
Test
- Documents Légaux
Il n’est pas un secret que les avocats manipulent souvent d’énormes quantités de texte. Nous avons donc décidé de commencer nos tests de Humata avec un document de 15 pages du Centre National de la Constitution des États-Unis. Ce document décrit les 27 amendements à la Constitution des États-Unis.

Nous avons commencé par vérifier la compréhension du contenu du document par Humata. Comme vous pouvez le voir, le document met en évidence quatre périodes d’introduction des amendements. Nous avons donc demandé à Humata combien d’amendements ont été adoptés pendant l’ère progressiste.
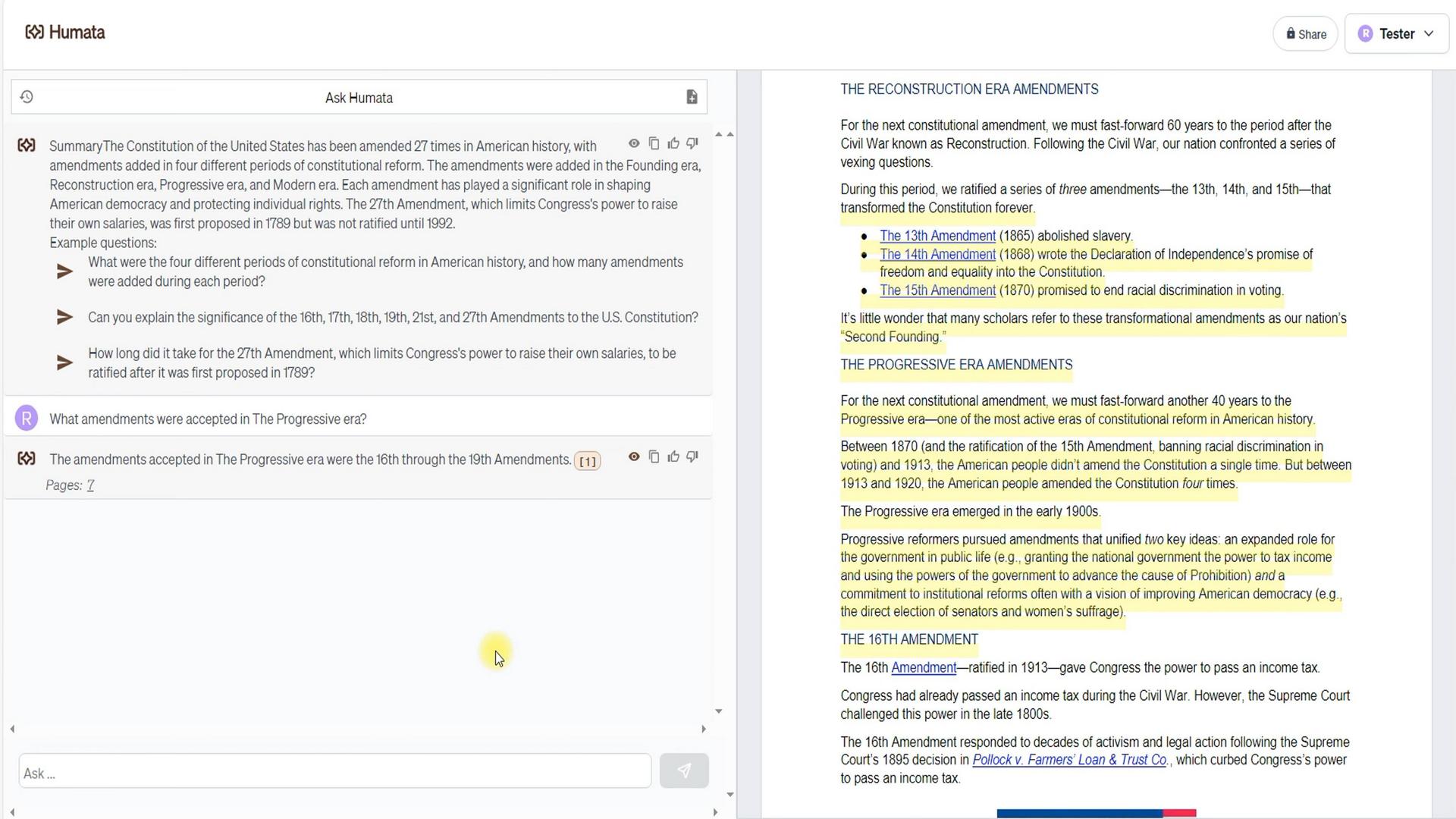
Réponse : 4. De plus, il convient de noter qu’il s’agissait des amendements n°16 à n°19. Remarquez également que Humata a fourni un lien vers sa source d’information, qui nous mène à la page 7. Ainsi, entre la première page avec une brève description et la septième avec une description détaillée, Humata a opté pour une source plus détaillée.
Ensuite, nous avons testé la capacité de Humata à traiter le texte et nous lui avons demandé de narrer brièvement l’histoire du 27e amendement. Ce document accorde beaucoup d’attention à cela.

Réponse : Dans la première phrase, nous obtenons une description de l’essence de l’amendement. Ainsi, Humata ne se contente pas de copier le texte approprié pour la réponse mais le donne de manière structurée. Dans la phrase suivante, la réponse est complétée par des informations supplémentaires sur les 200 ans d’attente pour l’adoption de l’amendement.
Ensuite, nous avons testé l’attention aux détails de Humata. Nous avons demandé si James Maddson était effectivement l’auteur du 27e amendement mais avons délibérément mal orthographié le nom.

Réponse : Humata a considéré cela comme une simple faute de frappe et l’a ignoré. Cependant, il a correctement identifié le nom du législateur dans la réponse.
Nous avons donc essayé une autre approche. Nous avons décidé de prendre un nom de sonorité similaire, par exemple, Jim Morrison, et de demander s’il était l’auteur, disons, du 21e amendement.

Réponse : Humata n’a pas pu fournir de réponse car il n’a pas trouvé d’informations pertinentes dans le document.
Pour tester si Humata est cohérent dans ses réponses, nous avons posé la même question mais avons introduit une série d’erreurs grammaticales.

Réponse : C’est la même chose qu’auparavant. C’est le comportement correct pour de tels systèmes linguistiques car les fautes de frappe sont assez courantes et de tels systèmes devraient comprendre les requêtes même si elles sont erronées.
Enfin, une question délicate. “Qui était l’auteur du 21e amendement?”

Réponse : Correct, l’amendement n’a pas d’auteur spécifique. Au fait, nous tenons à souligner que la description de cet amendement dans le document suit intentionnellement le 18e amendement qu’il a abrogé. Ainsi, Humata navigue excellemment à la fois dans la structure du document et dans ses éléments de contenu.
Après cela, nous avons également réalisé de nombreux tests similaires avec d’autres types de documents textuels. Il n’est pas nécessaire de les parcourir à nouveau car les résultats étaient similaires à la façon dont Humata s’est comporté lorsqu’il traitait des documents légaux. Nous ne soulignerons donc que les aspects les plus intéressants de ces tests à l’avenir.
- Medical Documents
Pour ce test, nous avons utilisé une brochure médicale de 21 pages sur les AVC.
La première question a révélé que Humata peut formuler des réponses même lorsque les informations nécessaires ne sont pas directement indiquées dans le document. Comme vous pouvez le voir, il a utilisé environ six paragraphes et a pris la dernière phrase comme fondement de la réponse. Humata a également réussi à organiser des informations provenant de différentes parties du document, les consolidant en une seule réponse.
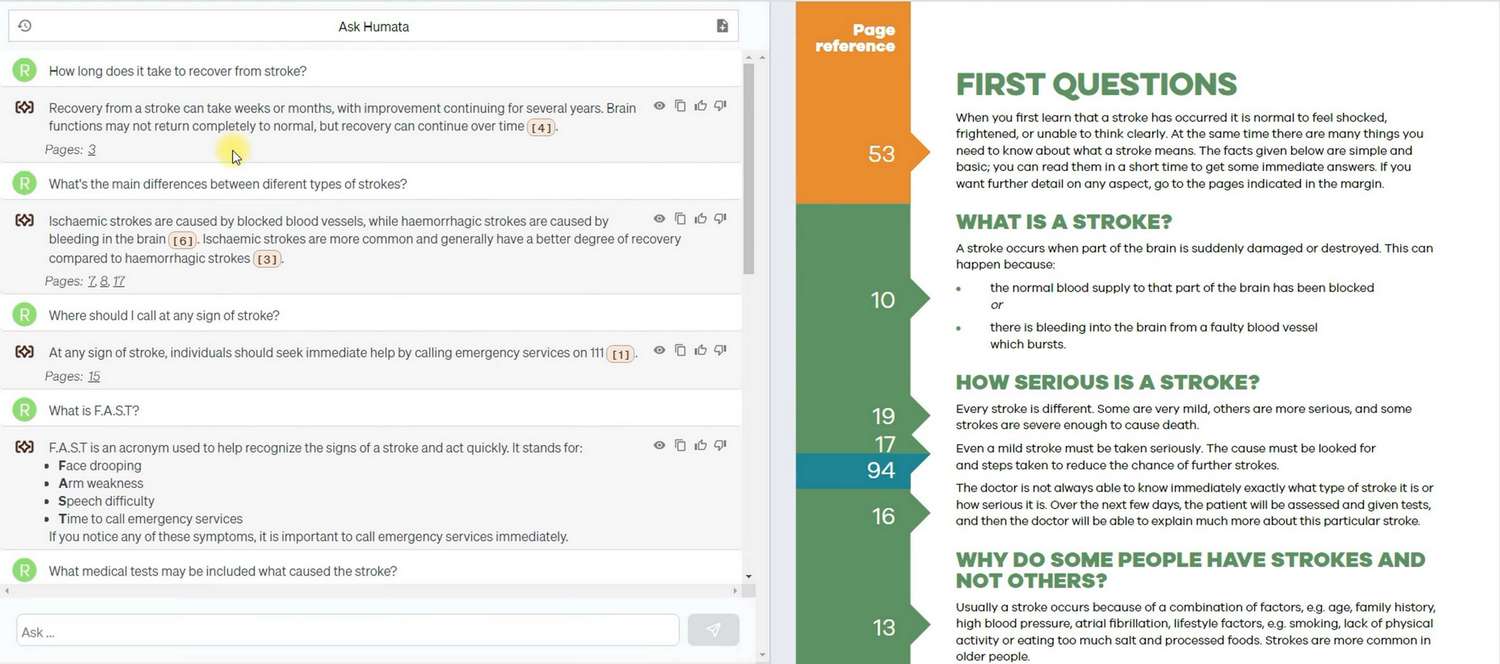
Cependant, un aspect négatif du modèle de langue est apparu ici. Il y avait une page dans le document sur laquelle une consultation médicale est requise pour un patient ayant subi un AVC. Nous avons formulé une question avec deux options délibérément fausses, et Humata en a choisi une comme réponse, en utilisant une source de données externe comme argument. Nous avons vérifié cette source, et les données étaient correctes, mais personnellement, nous n’avons pas aimé que Humata ne se soit pas uniquement appuyé sur les données de ma source. De plus, nous avons dû passer du temps à rechercher la source de données externe utilisée par Humata, car le lien fourni était déjà inaccessible.
- Recettes Culinaire
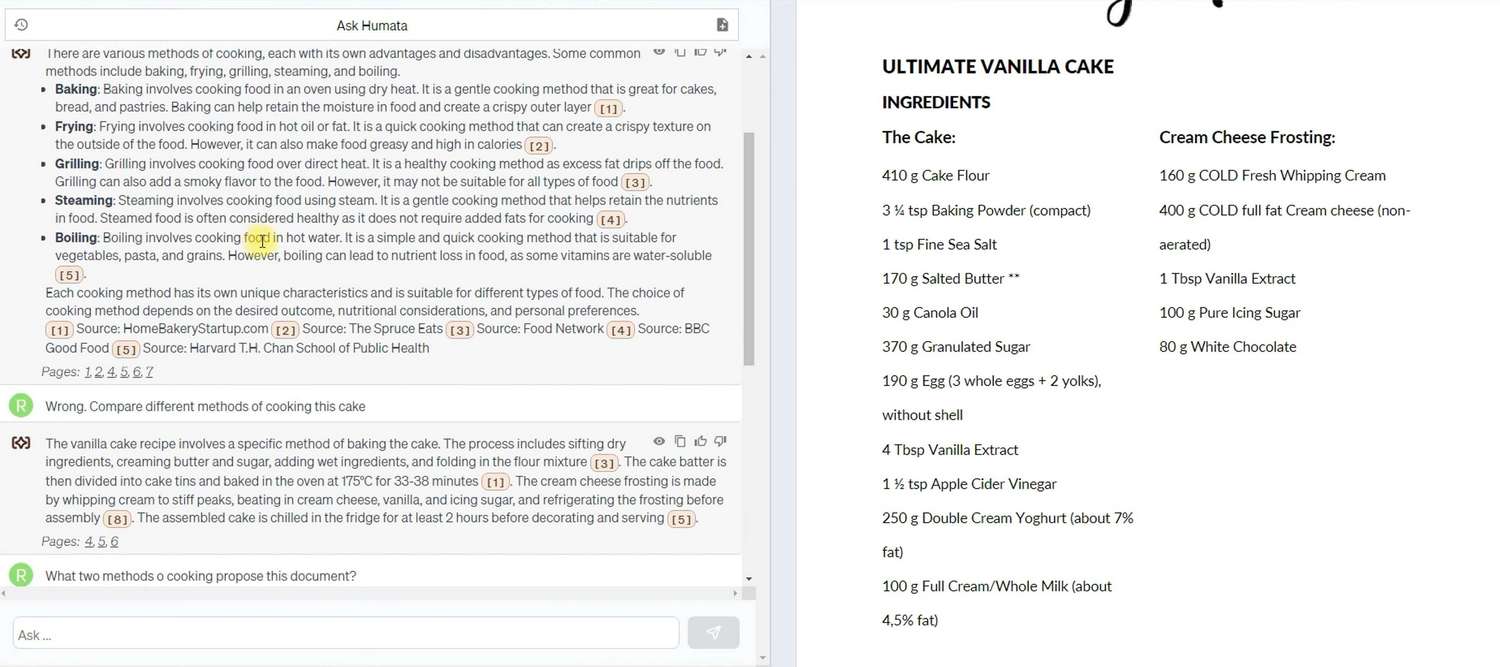
Dans ce cas, Humata a été encore plus proactif dans l’utilisation de données externes, mais en affinant la question, il a été convaincu de n’utiliser que les informations fournies dans le document. Tout au long de ces tests, les capacités de Humata pour l’auto-apprentissage et la compréhension du contexte des requêtes des utilisateurs étaient évidentes, similaires aux modèles de langage populaires.
- Textes Ordinaires
Ce document contenait plusieurs avis sur un seul établissement aux États-Unis. Il y avait peu de structuration dans le document et un langage informel. Comme vous pouvez le voir, dans la première question, Humata a décrit exhaustivement le document et sa structure, condensant l’essence de 20 lignes de texte en 6.
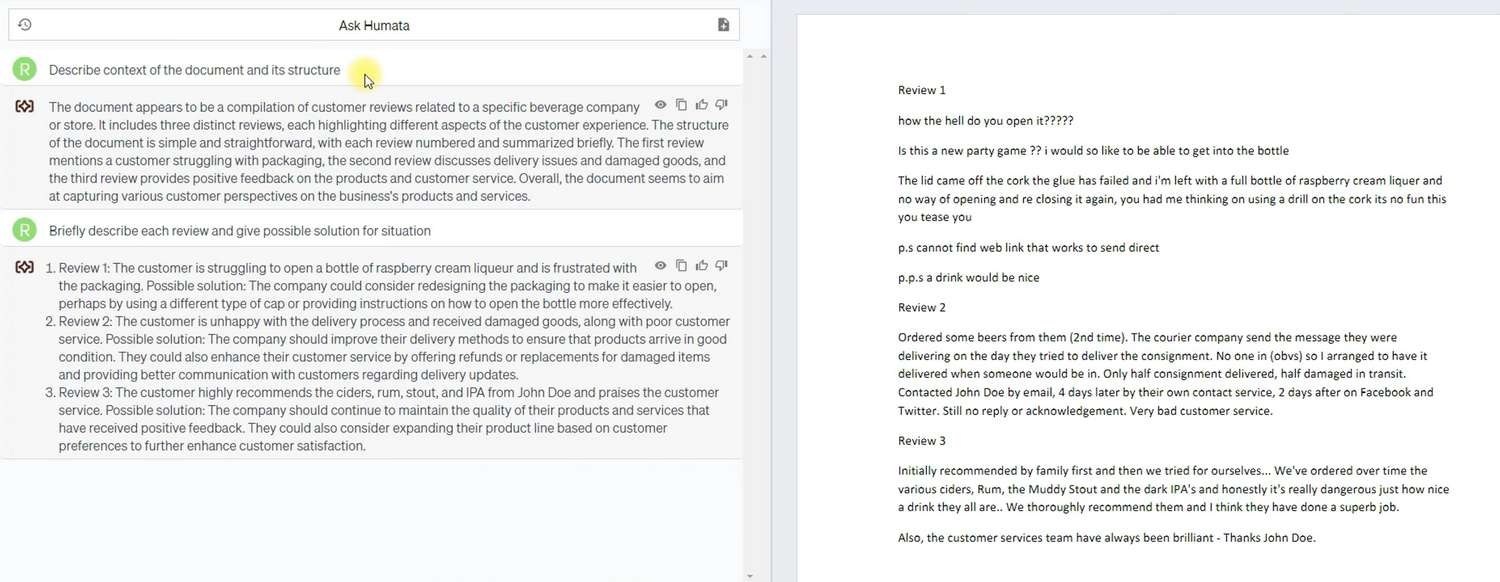
De plus, Humata a été capable de résumer efficacement les avis sans en perdre l’essence et, plus important encore, a fourni des recommandations selon la demande sur la manière dont le propriétaire devrait répondre à ces avis. Comme vous pouvez le constater, les conseils donnés sont assez généraux, mais néanmoins, cela confirme que, en plus des données externes et du document de l’utilisateur, Humata dispose d’une grande quantité de ses propres données qu’il peut fournir aux utilisateurs.
Aspects Techniques
Étant donné que Humata est un service basé sur le cloud, ses principales caractéristiques techniques sont la commodité et la sécurité. Nos tests ont montré que Humata a une interface minimale, ce qui le rend facile à utiliser. De plus, bien qu’il se positionne comme un service pour les documents PDF, il est également compatible avec les fichiers Microsoft Word et PowerPoint.
Il convient également de noter que nos tests ont montré qu’il fonctionne mieux avec des documents ayant un formatage de texte clair. Si votre fichier PDF, par exemple, est un document scanné non formaté, vous devrez utiliser la fonction OCR, qui n’est disponible que dans le plan Team. OCR peut également être nécessaire si Humata détecte un grand nombre de diagrammes ou de schémas dans votre document. Cependant, vous pouvez toujours utiliser des solutions OCR tierces pour rendre vos documents compatibles avec Humata. N’hésitez pas à demander de l’aide dans les commentaires si vous avez besoin d’aide à ce sujet.
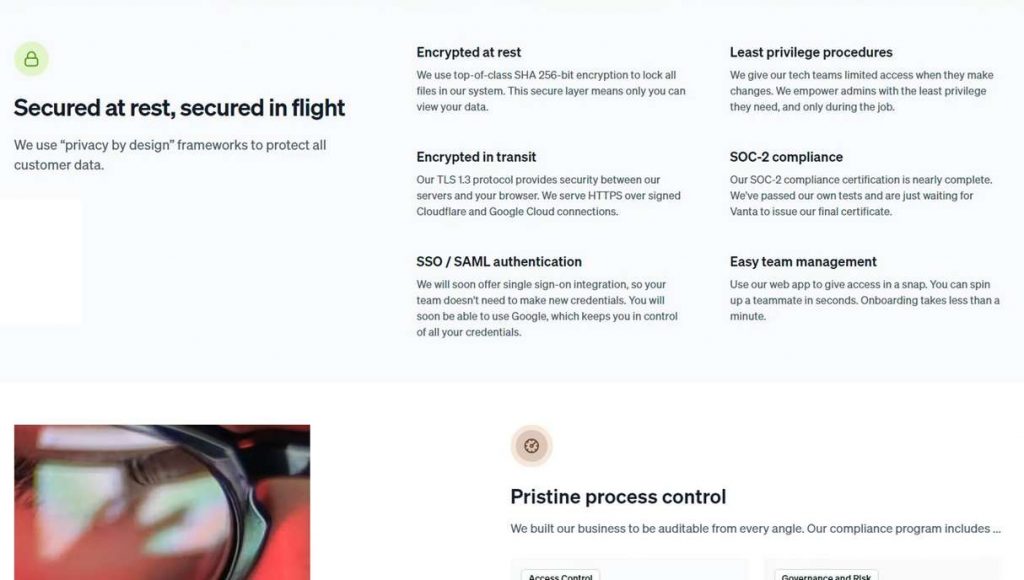
En ce qui concerne la sécurité, lorsque vous envoyez vos fichiers, ils sont cryptés à l’aide du protocole TLS 1.3, tandis que les fichiers sauvegardés sont protégés par l’algorithme de chiffrement SHA 256 bits. De plus, le service est actuellement soumis à diverses certifications de sécurité de l’industrie, y compris un audit SOC 2 – l’une des normes internationales de cybersécurité les plus strictes. En bref, cet audit examine tous les processus de l’entreprise en termes de leur impact sur la sécurité, la disponibilité, l’intégrité, la confidentialité et la confidentialité des données des utilisateurs.
Mais même avec toutes les certifications et audits, consultez votre service informatique avant de télécharger des données confidentielles sur Humata si vous êtes un client professionnel. Si vous êtes un utilisateur privé, évitez de télécharger des informations critiques, telles que des mots de passe, des données financières et des identifiants.
Prix
La base de la grille tarifaire de Humata est le quota pour le nombre de pages que vous pouvez scanner. Dans nos tests, nous avons utilisé le plan gratuit, qui permet de numériser 60 pages par mois. Le plan payant le moins cher est disponible uniquement pour les étudiants et coûte 2 $ par mois pour un quota de 200 pages avec la possibilité de scanner au-dessus de la limite au prix de 2 cents par page.
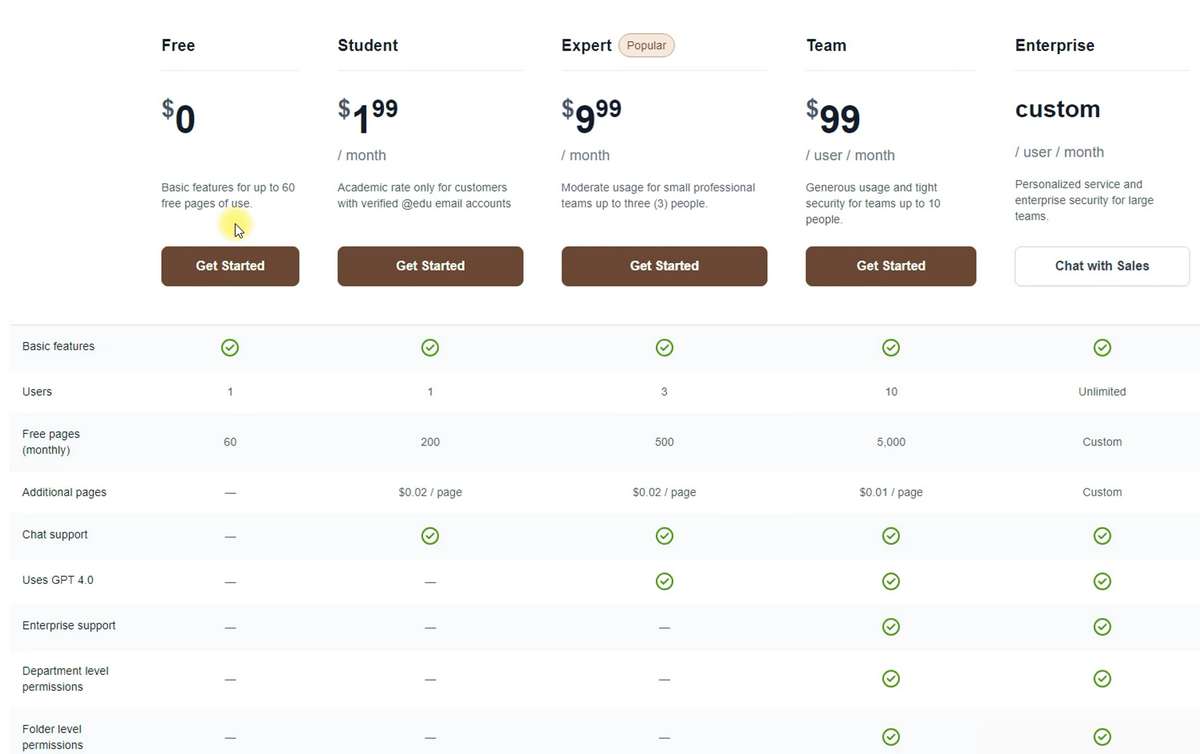
Le plan de base coûte 10 $ pour un quota de 500 pages, et en plus des avantages des plans précédents, il vous permet d’ajouter trois personnes au compte et d’accéder au modèle de langue GPT 4.0. Par conséquent, bien que cela ne soit pas directement indiqué dans les plans moins chers, il est probable que le modèle GPT 3.5 soit utilisé.
Enfin, le plan premium avec un quota de 5000 pages, réduit à 1 centime par numérisation au-dessus de la limite, et la possibilité d’ajouter jusqu’à 10 membres de l’équipe avec différents niveaux d’accès coûtera 100 $ par mois par utilisateur. Cela peut sembler un peu cher, mais pour les grandes entreprises, ce serait un prix acceptable pour la possibilité de créer une bibliothèque interactive de fichiers de travail avec une fonction OCR intégrée.
Conclusion
Humata est un produit qui semble simple en surface mais est assez complexe en interne. Il est compatible avec les principaux formats de document et peut reconnaître le texte à partir d’images si nécessaire. L’IA navigue dans la structure du document, comprend le contexte utilisé dans une situation donnée et est capable d’apprendre pour adapter les réponses aux requêtes spécifiques des utilisateurs.
Les moments négatifs ne peuvent être mis en évidence que par l’obsolescence des liens vers des sources de données externes et la possibilité de piéger le système dans une boucle logique lors de la formulation d’une question. Cependant, dans le cas de Humata, ce n’est pas un problème, car le principal objectif de ce service est l’analyse et le traitement de documents, dans lequel il excelle dans les tests.
Le public cible du service est constitué de personnes travaillant avec de grandes sources textuelles (comme les avocats, les médecins ou les ingénieurs), mais grâce à sa politique tarifaire flexible, Humata convient parfaitement à une utilisation quotidienne ou éducative.
